[root@zk01 ~]# java -version java version "1.8.0_162" Java(TM) SE Runtime Environment (build 1.8.0_162-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
检查hadoop版本
1 2 3 4 5 6 7
[root@zk01 ~]# hadoop version Hadoop 3.1.3 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579 Compiled by ztang on 2019-09-12T02:47Z Compiled with protoc 2.5.0 From source with checksum ec785077c385118ac91aadde5ec9799 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.1.3.jar
------------------------------------------------------------------------ [root@hadoop ~]# vi /usr/local/hbase/bin/hbase CLASSPATH=${CLASSPATH}:$JAVA_HOME/lib/tools.jar:/usr/local/hbase/lib/* 或 [root@hadoop ~]# sed -i "s/CLASSPATH=\${CLASSPATH}:\$JAVA_HOME\/lib\/tools.jar/CLASSPATH=\${CLASSPATH}:\$JAVA_HOME\/lib\/tools.jar:\/usr\/local\/hbase\/lib\/*/g" /usr/local/hbase/bin/hbase ------------------------------------------------------------------------
[root@hadoop ~]# hbase version SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/local/hbase/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] HBase 2.2.2 Source code repository git://6ad68c41b902/opt/hbase-rm/output/hbase revision=e6513a76c91cceda95dad7af246ac81d46fa2589 Compiled by hbase-rm on Sat Oct 19 10:10:12 UTC 2019 From source with checksum 4d23f97701e395c5d34db1882ac5021b
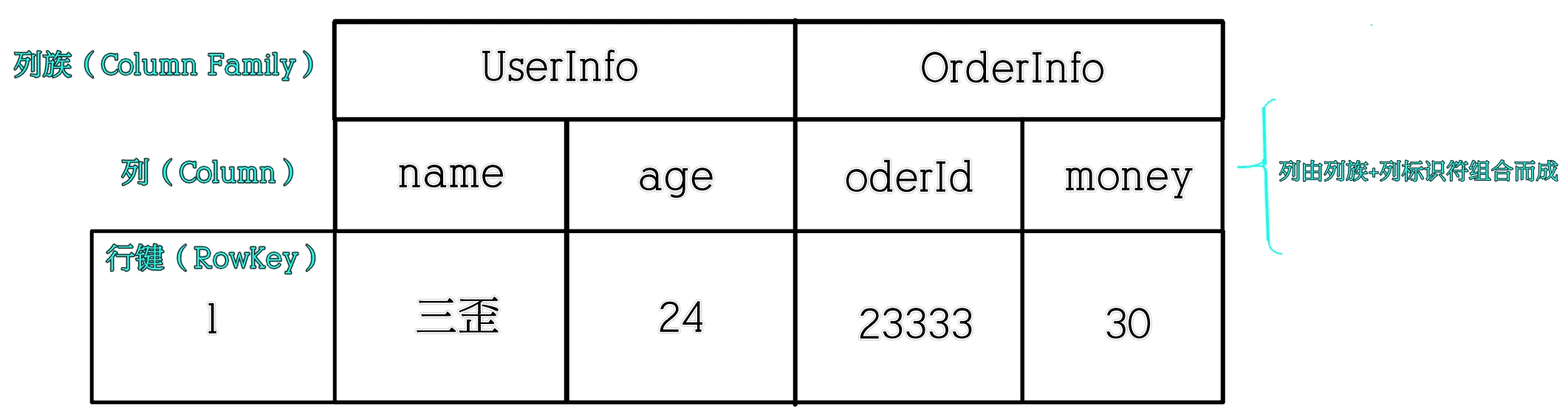
create 'order','userinfo','orderinfo' list put 'order','1','userinfo:name','sw' put 'order','1','userinfo:age','24' put 'order','1','orderinfo:id','23333' put 'order','1','orderinfo:money','30' scan 'order' ----------------------------------------------------------- hbase(main):017:0* create 'order','userinfo','orderinfo' Created table order Took 2.3102 seconds => Hbase::Table - order hbase(main):018:0> list TABLE order student 2 row(s) Took 0.0104 seconds => ["order", "student"] hbase(main):019:0> put 'order','1','userinfo:name','sw' Took 0.0326 seconds hbase(main):020:0> put 'order','1','userinfo:age','24' Took 0.0031 seconds hbase(main):021:0> put 'order','1','orderinfo:id','23333' Took 0.0036 seconds hbase(main):022:0> put 'order','1','orderinfo:money','30' Took 0.0031 seconds hbase(main):023:0> scan 'order' ROW COLUMN+CELL 1 column=orderinfo:id, timestamp=1679060732699, value=23333 1 column=orderinfo:money, timestamp=1679060732711, value=30 1 column=userinfo:age, timestamp=1679060732685, value=24 1 column=userinfo:name, timestamp=1679060732667, value=sw 1 row(s) Took 0.0116 seconds
修改数据
1 2 3 4 5 6 7
hbase(main):001:0> put 'student','s001','name','zhangxiaosan' Took 0.2879 seconds hbase(main):002:0> get 'student','s001','name' COLUMN CELL name: timestamp=1679061655288, value=zhangxiaosan 1 row(s) Took 0.0280 seconds
时间戳
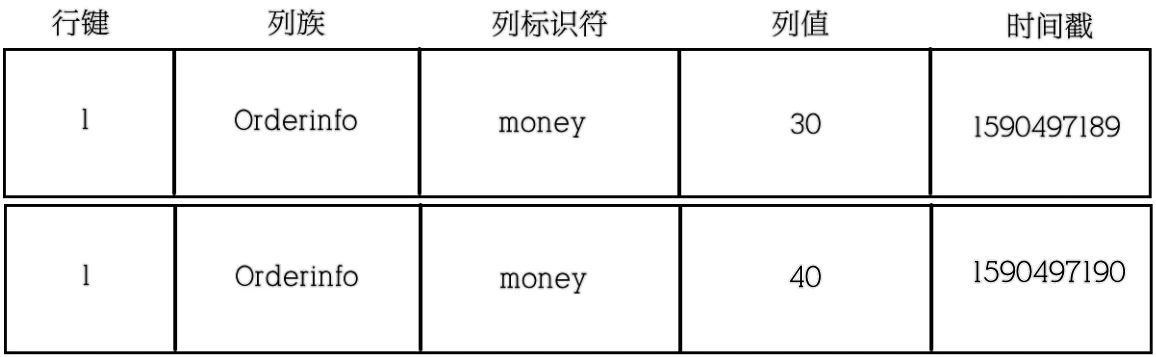
#数据添加到HBase的时候都会被记录一个时间戳,这个时间戳被我们当做一个版本。
当修改某一条的时候,本质上是往里边新增一条数据,记录的版本加一。
#现在要把这条记录的值改为40,实际上就是多添加一条记录,在读的时候按照时间戳读最新的记录
1 2 3 4 5 6 7 8 9 10 11
put 'order','1','orderinfo:money','40' get 'order','1','orderinfo:money'
hbase(main):008:0> put 'order','1','orderinfo:money','40' Took 0.0190 seconds hbase(main):009:0> get 'order','1','orderinfo:money' COLUMN CELL orderinfo:money timestamp=1679064515487, value=40 1 row(s) Took 0.0096 seconds
删除数据
name一定要加个:
1 2 3
scan 'student' delete 'student','s001','name:' get 'student','s001','name'
删除表
1 2 3
disable 'student' describe 'student' drop 'student'
tar -xf redis-5.0.5.tar.gz mv redis-5.0.5 /opt/redis cd /opt/redis yum install -y gcc automake autoconf libtool #编译安装 make && make install cd src [root@yjx48 src]# ./redis-server 5861:C 30 Mar 2023 08:49:48.699 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 5861:C 30 Mar 2023 08:49:48.699 # Redis version=5.0.5, bits=64, commit=00000000, modified=0, pid=5861, just started 5861:C 30 Mar 2023 08:49:48.699 # Warning: no config file specified, using the default config. In order to specify a config file use ./redis-server /path/to/redis.conf 5861:M 30 Mar 2023 08:49:48.699 * Increased maximum number of open files to 10032 (it was originally set to 1024). _._ _.-``__ ''-._ _.-`` `. `_. ''-._ Redis 5.0.5 (00000000/0) 64 bit .-`` .-```. ```\/ _.,_ ''-._ ( ' , .-` | `, ) Running in standalone mode |`-._`-...-` __...-.``-._|'` _.-'| Port: 6379 | `-._ `._ / _.-' | PID: 5861 `-._ `-._ `-./ _.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | http://redis.io `-._ `-._`-.__.-'_.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | `-._ `-._`-.__.-'_.-' _.-' `-._ `-.__.-' _.-' `-._ _.-' `-.__.-'
5861:M 30 Mar 2023 08:49:48.700 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
1 2 3 4 5 6 7 8 9
#另开一个会话 [root@yjx48 ~]# cd /opt/redis/src [root@yjx48 src]# ./redis-cli 127.0.0.1:6379> set hello world OK 127.0.0.1:6379> get hello "world" 127.0.0.1:6379> exit [root@yjx48 src]#
数据库管理
redis语法
1 2 3 4 5 6 7 8 9 10 11 12 13
#插入数据 set student:2015001:sname zhangsan get student:2015001:sname set student:2015001:sex male get student:2015001:sex #修改数据 set student:2015001:sname zhangxiaosan get student:2015001:sname #删除数据 get set student:2015001:sname del set student:2015001:sname get set student:2015001:sname #没数据了
Hash数据库
student表
1 2 3 4 5
2015001={ name=zhangsan sex=male age=23 }
插入和查询数据
1 2 3 4 5 6
hset student:2015001 name zhangsan hset student:2015001 sex male hset student:2015001 age 23 hget student:2015001 name hget student:2015001 sex hgetall student:2015001
修改数据
1 2
hset student:2015001 sex female hget student:2015001 sex female
删除数据
1 2 3
hdel student:2015001 sex hget student:2015001 sex #无数据
#mongodb没有创建数据库命令 > use school switched to db school #创建集合,同时会自动创建以上的数据库 > db.createCollection('student') { "ok" : 1 } > show dbs admin 0.000GB config 0.000GB local 0.000GB school 0.000GB > show collections Student
cd yum remove mariadb-libs.x86_64 -y yum install -y net-tools mkdir mysql tar -xf mysql-5.7.37-1.el7.x86_64.rpm-bundle.tar -C mysql cd mysql rpm -ivh mysql-community-common-5.7.37-1.el7.x86_64.rpm rpm -ivh mysql-community-libs-5.7.37-1.el7.x86_64.rpm rpm -ivh mysql-community-libs-compat-5.7.37-1.el7.x86_64.rpm rpm -ivh mysql-community-client-5.7.37-1.el7.x86_64.rpm rpm -ivh mysql-community-devel-5.7.37-1.el7.x86_64.rpm rpm -ivh mysql-community-server-5.7.37-1.el7.x86_64.rpm systemctl enable --now mysqld grep 'temporary password' /var/log/mysqld.log mysqladmin -uroot -p'darm4hb.2Rsy' password 'Yjx@666.' mysql -uroot -pYjx@666. #给root用户授权 grant all privileges on *.* to 'root'@'localhost' identified by 'Yjx@666.' with grant option; grant all privileges on *.* to 'root'@'%' identified by 'Yjx@666.' with grant option; flush privileges; create database hive; exit
配置和启动hive
1 2 3 4 5 6 7 8
cd tar -xf mysql-connector-java-5.1.40.tar.gz cp mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar /usr/local/hive/lib/ mv /usr/local/hive/lib/guava-19.0.jar{,.bak} cp /usr/local/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/hive/lib start-all.sh schematool -dbType mysql -initSchema hive





 微信
微信 支付宝
支付宝