Hadoop 3.3.5部署
前情提要
本次实验采用Ubuntu 24.04LTS,自行安装
Ubuntu 24.04.02 LTS 初始化安装 | 严千屹博客
本笔记分伪分布和分布式两大块,但建议从头开始观看
文章所需资源可点击这里 下载
伪分布主机拓扑
主机名
ip(NAT)
内存
硬盘
qianyios
192.168.48.128
7G
100G
分布式主机拓扑
机名
ip(NAT)
内存
硬盘
master
192.168.48.128
6G
100G
slave
192.168.48.129
6G
100G
基础初始化
简单部署一个单节点的hadoop,然后打快照,后续给伪分布和分布式做基础底座
由于本系统在Ubuntu 24.04.02 LTS 初始化安装 | 严千屹博客 已经进行了设置阿里源和关闭防火墙,这里就不再赘述了
切换root用户
1 2 3 qianyios@qianyios:~$ su - root 密码: root@qianyios:~#
基础配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 cat >init.sh<<"EOF" # !/bin/bash sed -i 's/^#*PermitRootLogin.*/PermitRootLogin yes/' /etc/ssh/sshd_config sed -i 's/^#*PasswordAuthentication.*/PasswordAuthentication yes/' /etc/ssh/sshd_config systemctl restart ssh # 添加 hosts echo "192.168.48.128 qianyios" >> /etc/hosts echo "已添加 hosts 条目。" # 设置主机名 hostnamectl set-hostname qianyios echo "主机名已设置为 qianyios。" # 安装 sshpass apt install -y sshpass || { echo "安装 sshpass 失败"; exit 1; } echo "sshpass 安装完成。" # 目标主机列表 hosts=("qianyios") # 密码 password="123456" # 生成 SSH 密钥对 ssh-keygen -t rsa -N "" -f ~/.ssh/id_rsa echo "SSH 密钥对已生成。" # 循环遍历目标主机 for host in "${hosts[@]}" do echo "正在为 $host 配置免密登录..." sshpass -p "$password" ssh-copy-id -o StrictHostKeyChecking=no "$host" || { echo "复制公钥到 $host 失败"; exit 1; } sshpass -p "$password" ssh -o StrictHostKeyChecking=no "$host" "echo '免密登录成功'" || { echo "验证免密登录失败"; exit 1; } done reboot EOF bash init.sh
测试免密登入
1 2 3 4 5 6 7 root@qianyios:~# ssh qianyios Welcome to Ubuntu 24.04.2 LTS (GNU/Linux 6.11.0-17-generic x86_64) ...... Last login: Tue Feb 25 00:02:32 2025 from 127.0.0.1 root@qianyios:~#
下载所需资源 并解压到/root/hadoop/下,如下图
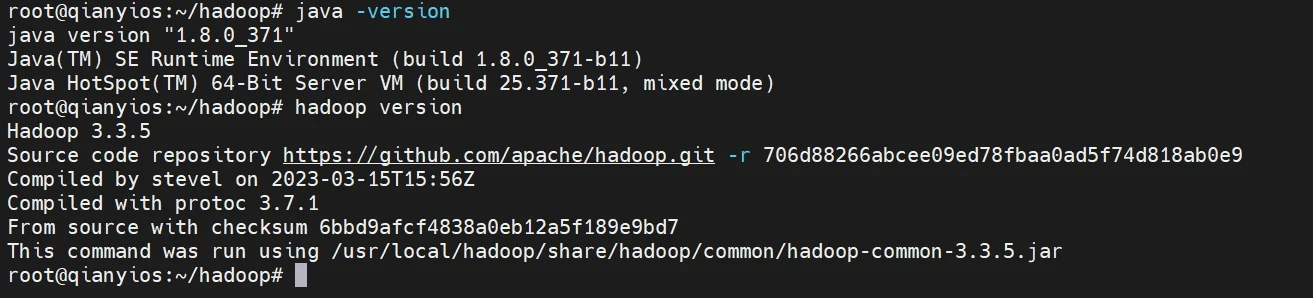
安装java环境和hadoop
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 cd /root/hadoopmkdir /usr/lib/jvmtar -xf /root/hadoop/jdk-8u371-linux-x64.tar.gz -C /usr/lib/jvm echo "export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_371" >> /etc/profileecho "export PATH=\$JAVA_HOME/bin:\$PATH" >> /etc/profilesource /etc/profilejava -version tar -zxf hadoop-3.3.5.tar.gz -C /usr/local mv /usr/local/hadoop-3.3.5/ /usr/local/hadoopecho "export HADOOP_HOME=/usr/local/hadoop" >> /etc/profileecho "export PATH=\$HADOOP_HOME/bin/:\$HADOOP_HOME/sbin/:\$PATH" >> /etc/profilesource /etc/profilehadoop version
成功图
这时候关机
打个快照,方便做分布式部署,如果你要做分布式的直接跳到4.分布式
伪分布
开机吧!
编写配置文件
编写cort-site.yaml文件
修改下面hdfs://qianyios:9000中的qianyios为你的主机名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 cat > /usr/local/hadoop/etc/hadoop/core-site.xml<< "EOF" <?xml version="1.0" encoding="UTF-8" ?> <?xml-stylesheet type ="text/xsl" href="configuration.xsl" ?> <configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://qianyios:9000</value> </property> </configuration> EOF
编写hdfs-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 cat >/usr/local/hadoop/etc/hadoop/hdfs-site.xml<<"EOF" <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration> EOF
启动hdfs服务
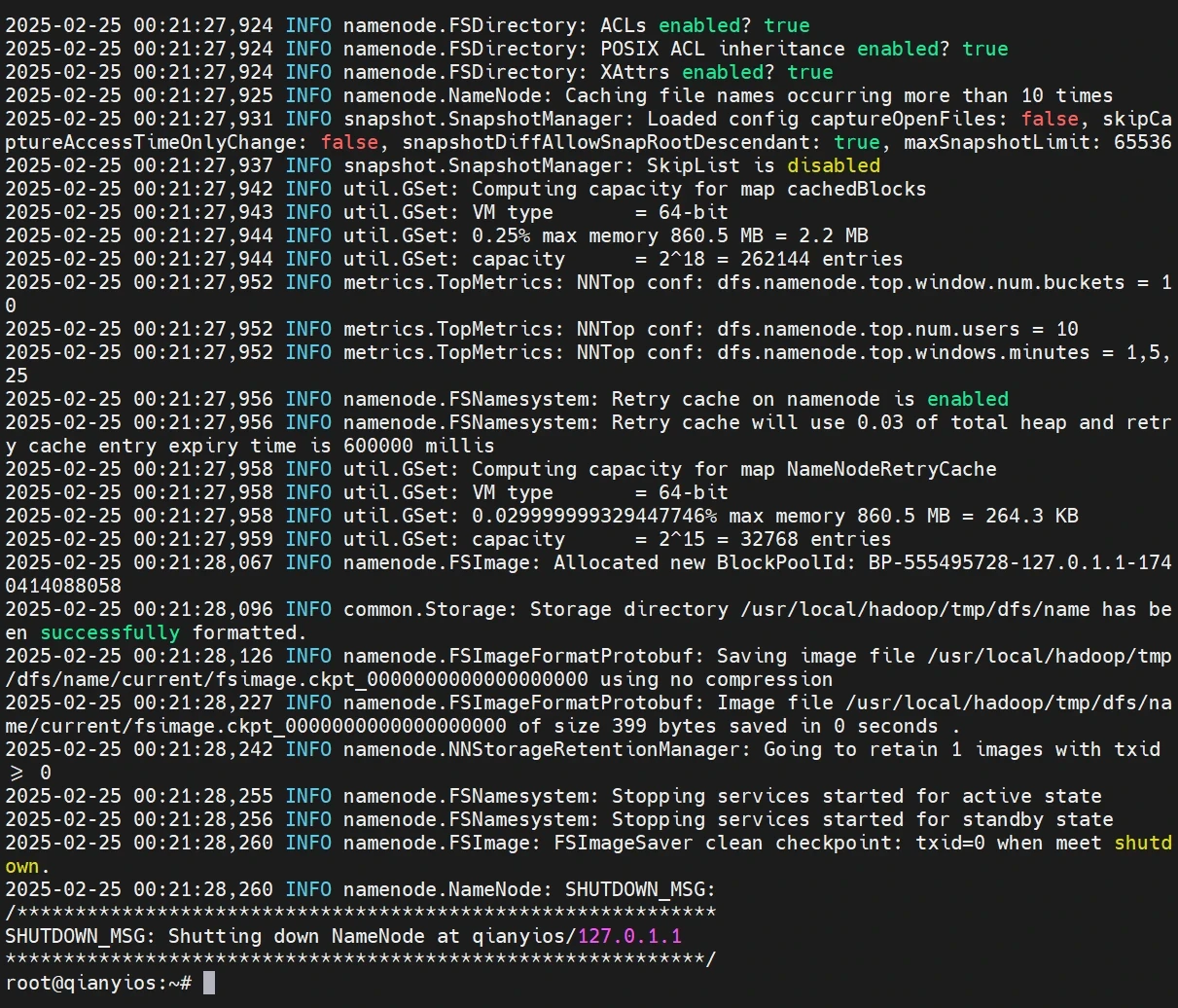
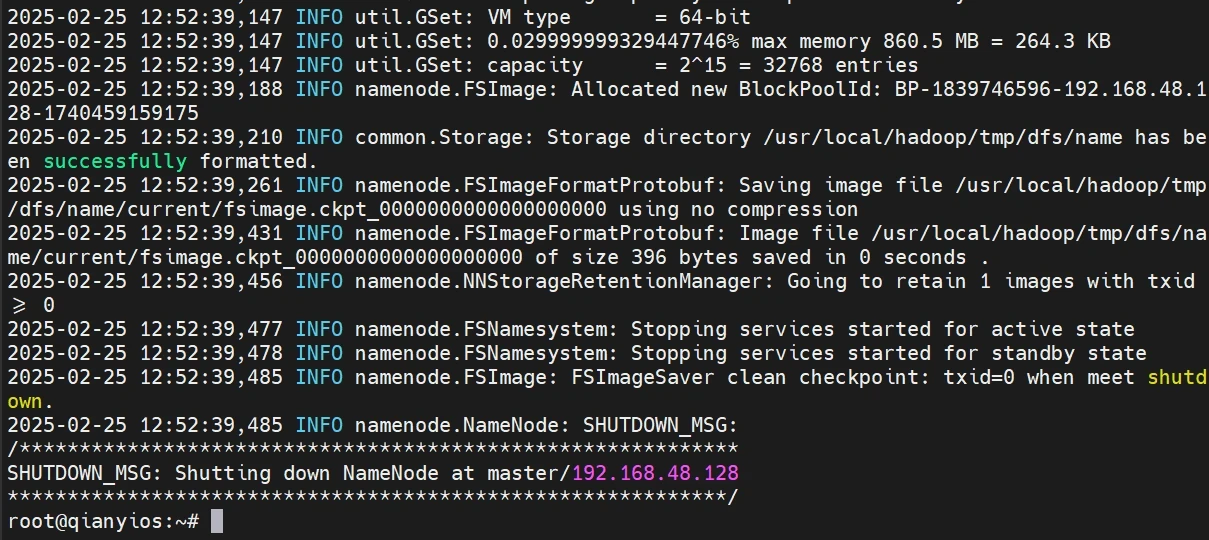
hadoop初始化
这条命令只需要运行一次,以后都不要再运行了!!!!!!
这条命令只需要运行一次,以后都不要再运行了!!!!!!
这条命令只需要运行一次,以后都不要再运行了!!!!!!
添加环境变量
1 2 3 4 5 6 echo "export HDFS_NAMENODE_USER=root" >> /etc/profileecho "export HDFS_DATANODE_USER=root" >> /etc/profileecho "export HDFS_SECONDARYNAMENODE_USER=root" >> /etc/profileecho "export YARN_RESOURCEMANAGER_USER=root" >> /etc/profileecho "export YARN_NODEMANAGER_USER=root" >> /etc/profilesource /etc/profile
修改hadoop配置文件
1 echo "export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_371" >> /usr/local/hadoop/etc/hadoop/hadoop-env.sh
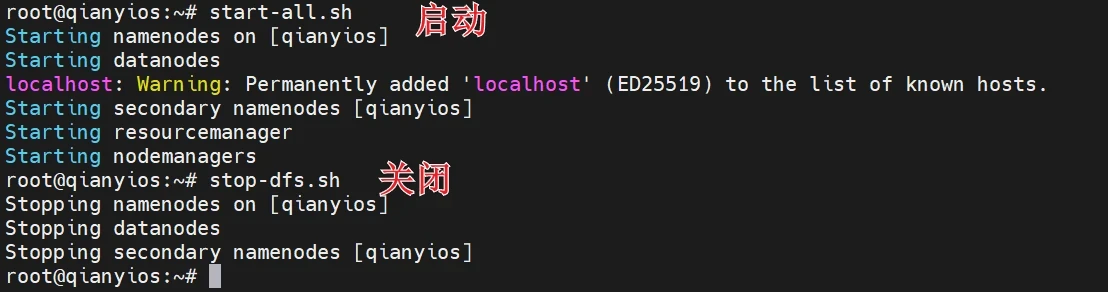
启动hadoop
localhost: Warning: Permanently added 'localhost' (ED25519) to the list of known hosts.
这是一个 SSH 的警告信息,表明 SSH 客户端首次连接到 localhost 时,将 localhost 的主机密钥(使用 ED25519 算法生成)添加到了 known_hosts 文件中。
这是 SSH 的正常行为,用于防止中间人攻击。每次 SSH 客户端连接到一个新主机时,都会将主机的密钥记录下来。
启动historyserver服务
1 2 3 start-all.sh mapred --daemon start historyserver
关闭用
1 mapred --daemon stop historyserver
正常启动hadoop你会看到如下服务
1 2 3 4 5 6 7 8 root@qianyios:~# jps 14050 NodeManager 10245 JobHistoryServer 13894 ResourceManager 13255 NameNode 13449 DataNode 13673 SecondaryNameNode 14606 Jps
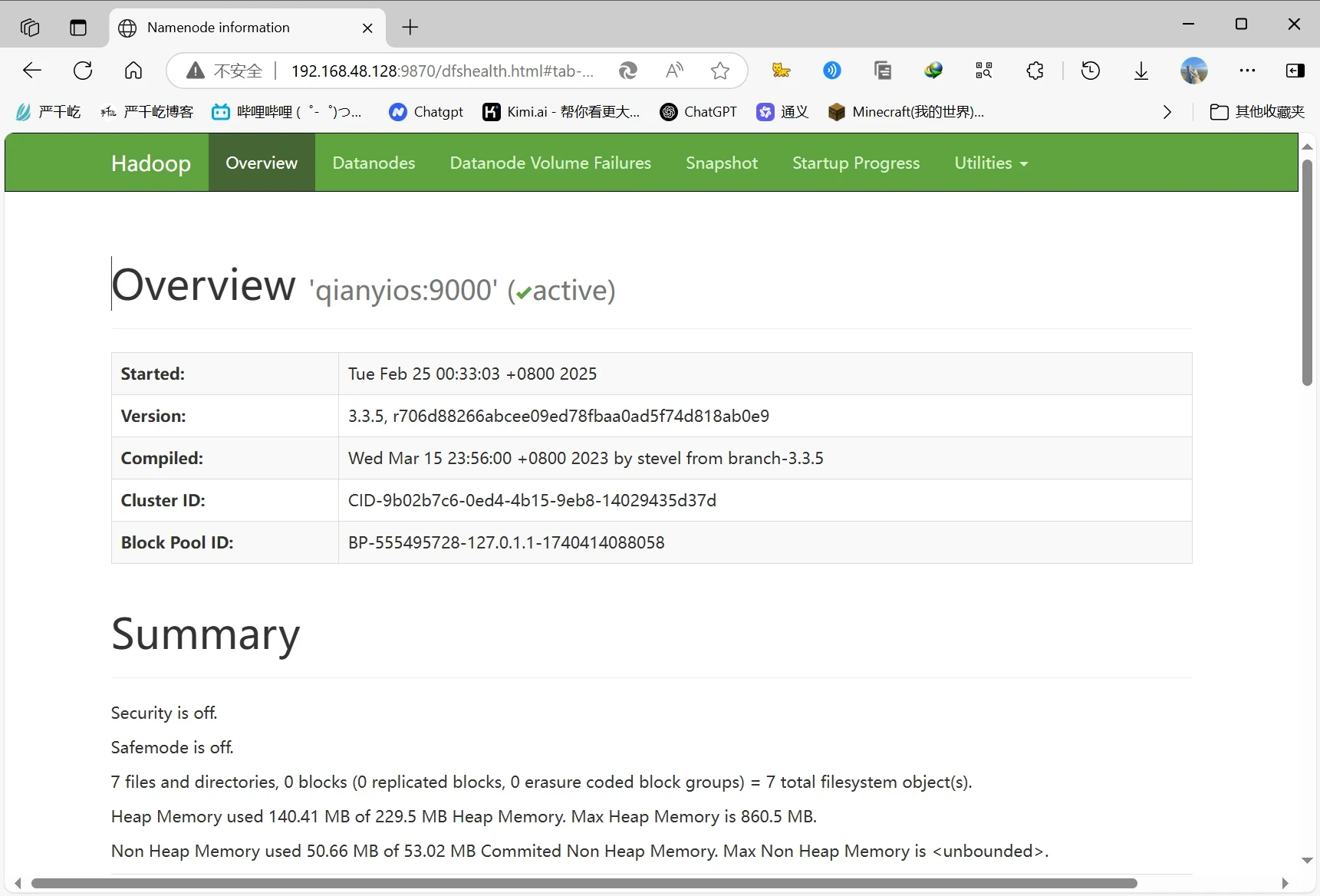
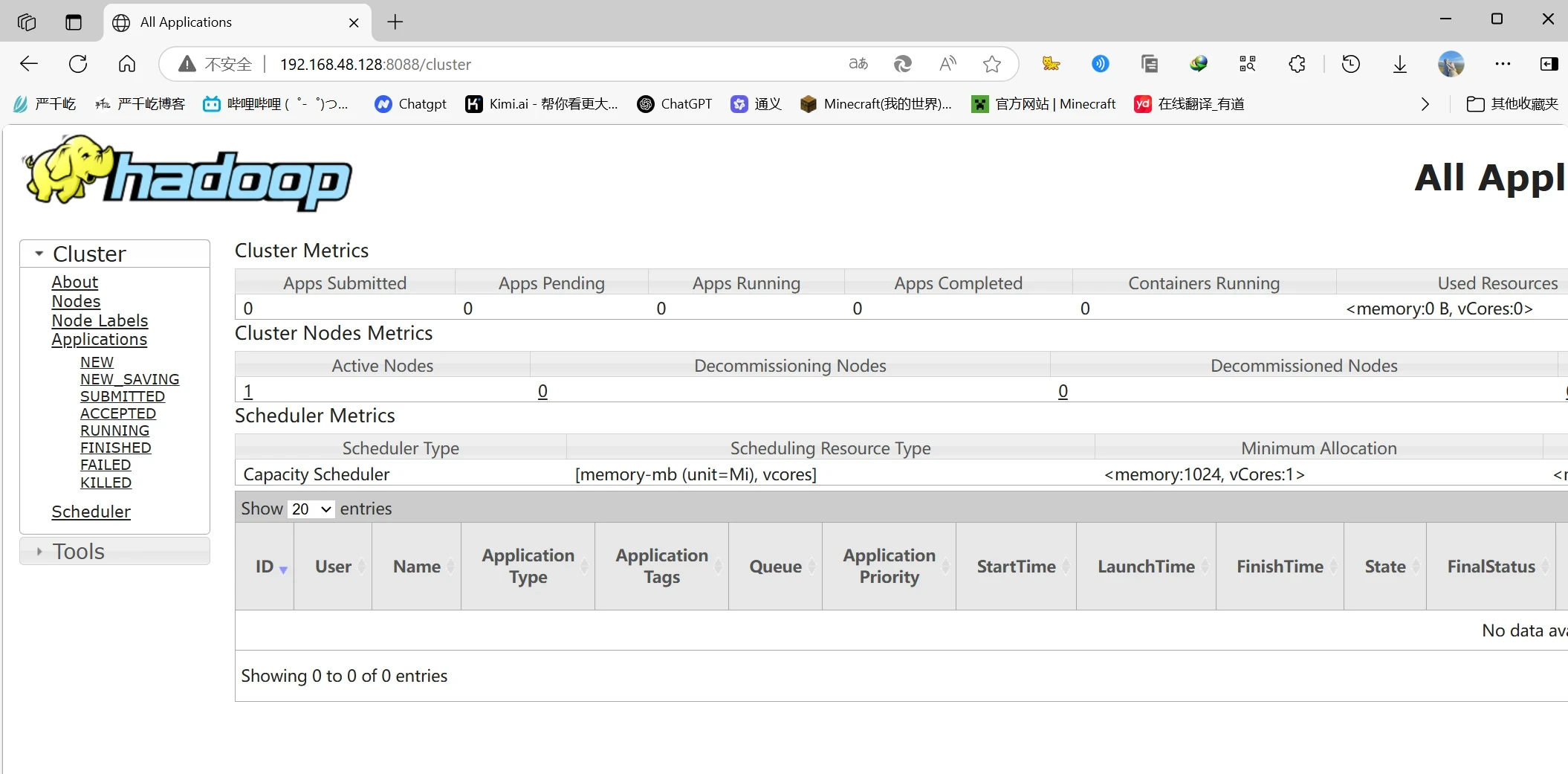
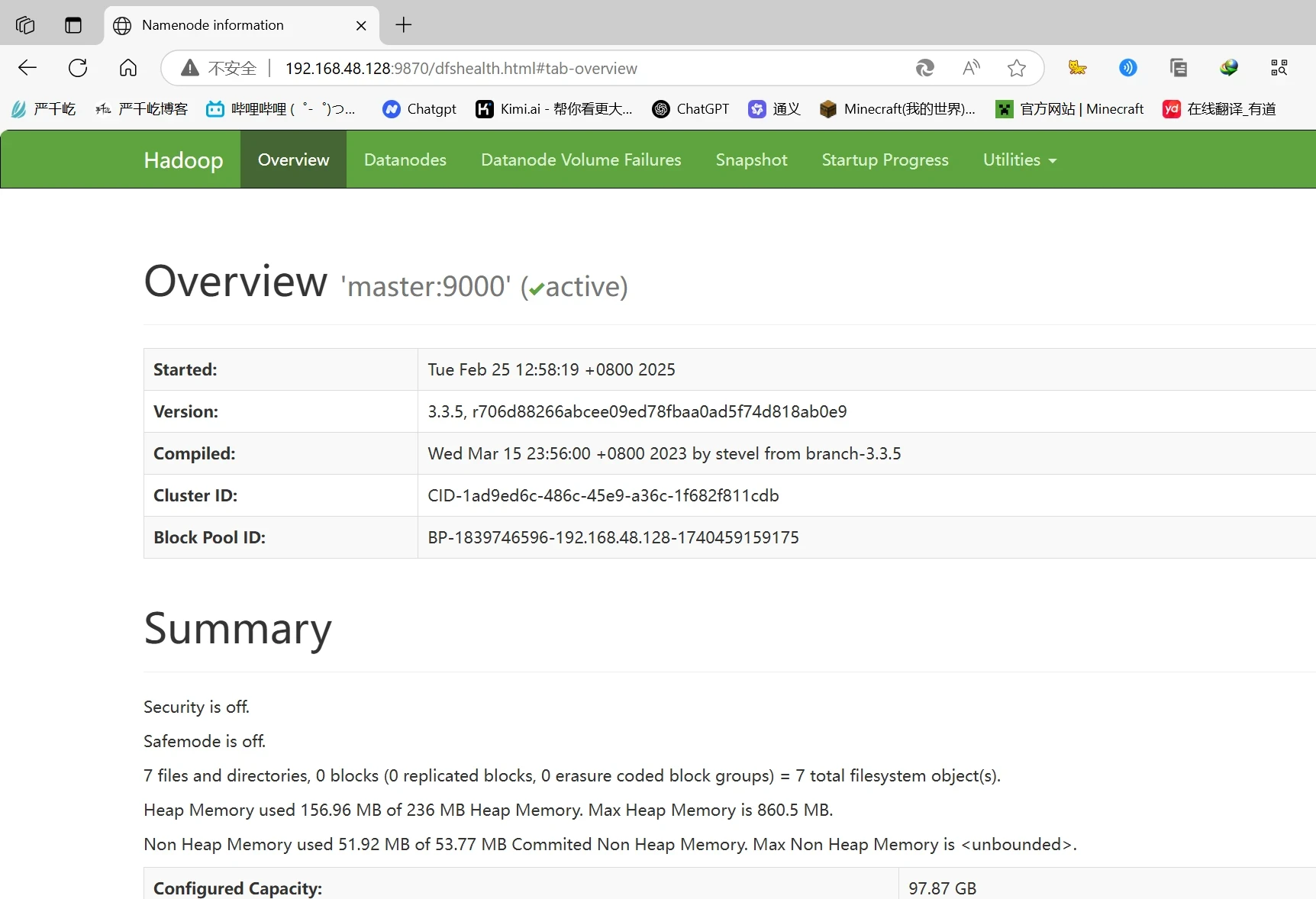
访问网页ip:9870查看hdfs
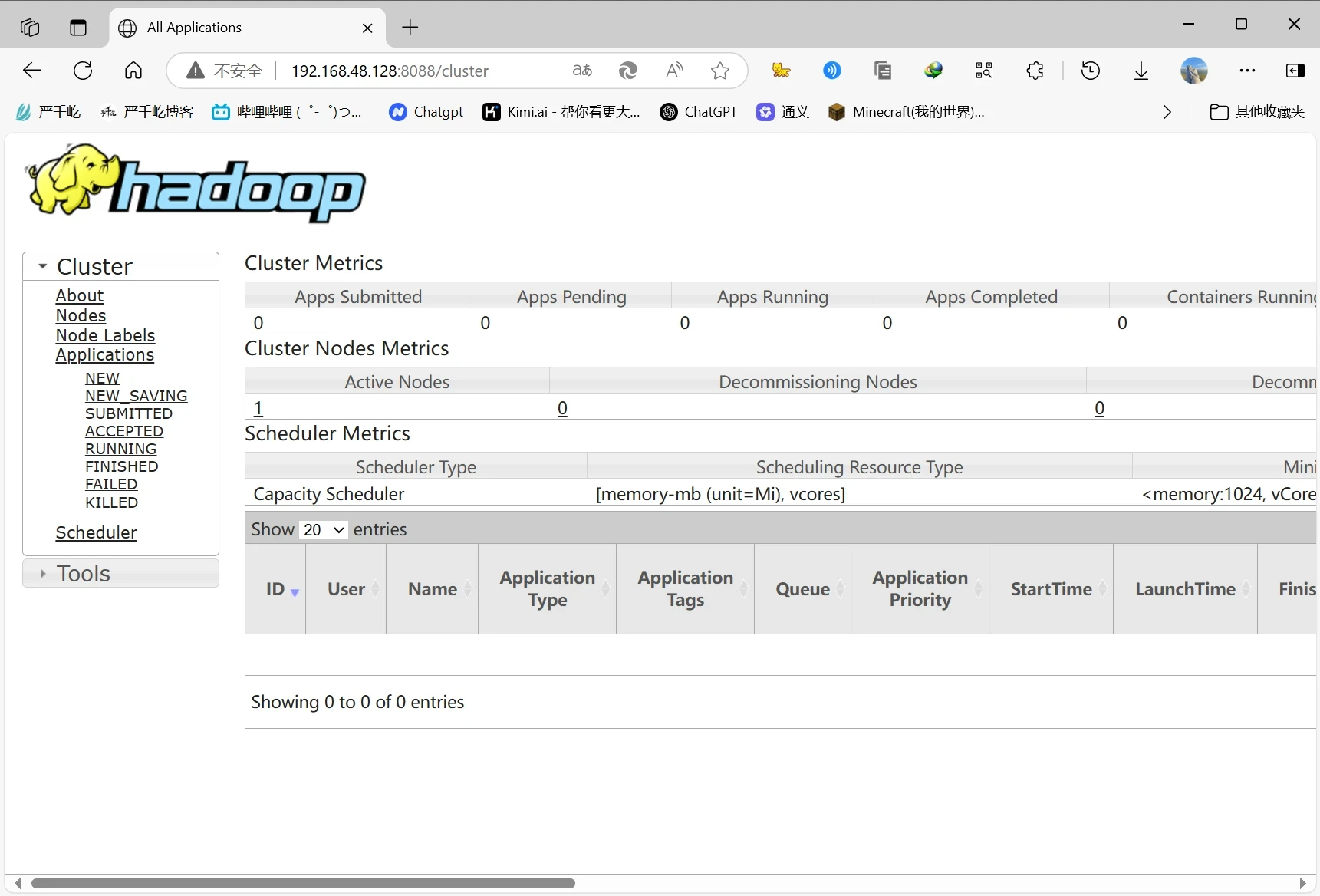
访问网页ip:8088查看hadoop
至此伪分布hadoop就搞定了,这时候你要在你这里打上一个伪分布的快照
分布式
前情提要
机名
ip(NAT)
内存
硬盘
master
192.168.48.128
6G
100G
slave
192.168.48.129
6G
100G
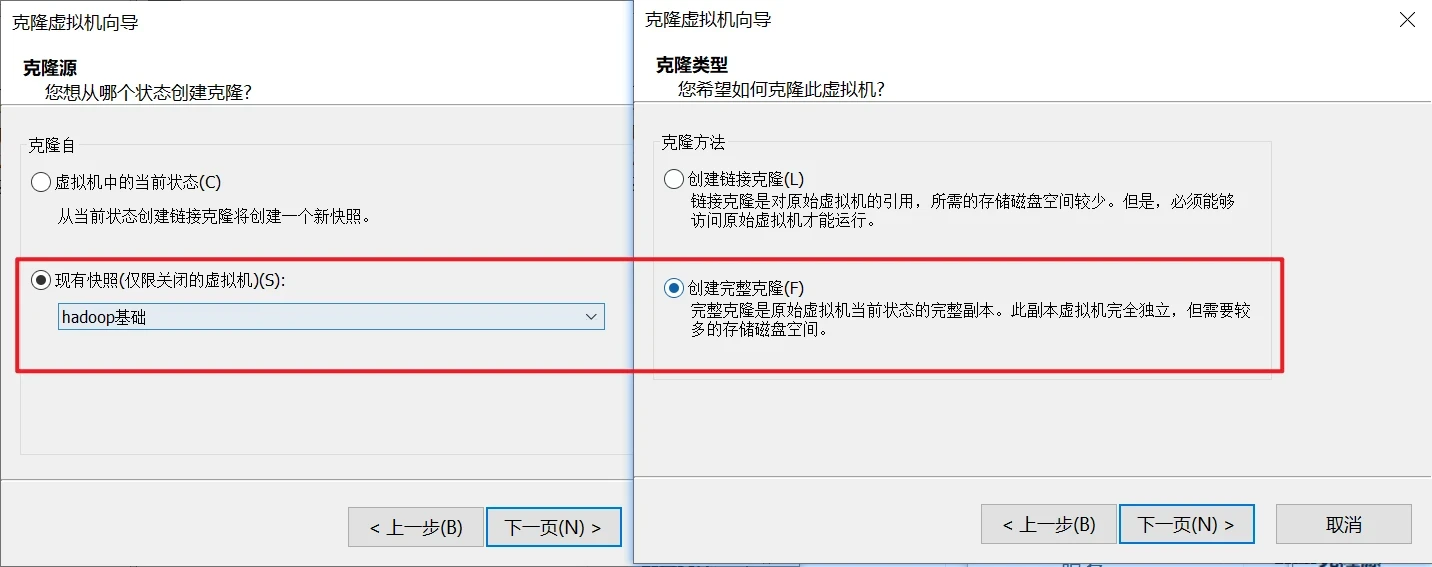
由于前面不是做了一个hadoop的一个基础快照吗,这时候你就对那个基础快照进行完整克隆两个出来,分别命名为master和slave
这时候先开slave,master不要开
1 vim /etc/netplan/01-network-manager-all.yaml
ip改成192.168.48.129
1 2 3 4 5 6 7 8 9 10 11 12 13 # Let NetworkManager manage all devices on this system network: ethernets: ens33: addresses: [192.168.48.129/24] dhcp4: false nameservers: addresses: [192.168.48.2, 114.114.114.114] routes: - to: default via: 192.168.48.2 version: 2 renderer: NetworkManager
重启网卡
这时候再把master开机,接着就可以进行基础操作了
基础操作
以下我会提前告诉你哪些是哪个节点要操作的命令
操作节点:=master和slave =
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 cat >fbsnit.sh <<"EOF" # !/bin/bash if [ $# -eq 1 ];then echo "设置主机名为:$1" else echo "使用方法:sh $0 主机名" exit 2 fi sudo sed -i '/qianyios/d' /etc/hosts # 这里你要改成你的ip grep -q "^192\.168\.48\.128\s\+master" /etc/hosts || echo "192.168.48.128 master" >> /etc/hosts grep -q "^192\.168\.48\.129\s\+slave" /etc/hosts || echo "192.168.48.129 slave" >> /etc/hosts hostnamectl set-hostname $1 # 设置免密 apt install -y sshpass || { echo "安装 sshpass 失败"; exit 1; } echo "sshpass 安装完成。" # 目标主机列表 hosts=("master" "slave") # 密码 password="123456" # 生成 SSH 密钥对 ssh-keygen -t rsa -N "" -f ~/.ssh/id_rsa echo "SSH 密钥对已生成。" # 循环遍历目标主机 for host in "${hosts[@]}" do echo "正在为 $host 配置免密登录..." sshpass -p "$password" ssh-copy-id -o StrictHostKeyChecking=no "$host" || { echo "复制公钥到 $host 失败"; exit 1; } sshpass -p "$password" ssh -o StrictHostKeyChecking=no "$host" "echo '免密登录成功'" || { echo "验证免密登录失败"; exit 1; } done reboot EOF
1 2 # master执行这个 bash fbsnit.sh master
修改配置文件
操作节点:master
1.修改workers文件
在Hadoop集群中,workers文件是一个非常重要的配置文件,它用于指定Hadoop集群中所有从节点(DataNode和TaskTracker/NodeManager)的主机名或IP地址
将slave修改成你自己的从节点的主机名
1 2 3 cat> /usr/local/hadoop/etc/hadoop/workers <<"EOF" slave EOF
2.修改core-site.xml
操作节点:master
将master修改成你自己的主节点的主机名
作用 :配置Hadoop的核心参数,主要涉及文件系统的访问和临时目录的设置。
fs.defaultFShdfs://<namenode-host>:<port>。这是Hadoop客户端访问HDFS的入口。hadoop.tmp.dir
1 2 3 4 5 6 7 8 9 10 11 12 13 cat > /usr/local/hadoop/etc/hadoop/core-site.xml<<"EOF" <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> </configuration> EOF
3.修改hdfs-site.xml
操作节点:master
将master修改成你自己的主节点的主机名
作用 :配置HDFS(Hadoop Distributed File System)的高级参数。
dfs.namenode.secondary.http-addressdfs.replicationdfs.namenode.name.dirdfs.datanode.data.dir
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 cat> /usr/local/hadoop/etc/hadoop/hdfs-site.xml<<"EOF" <configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:50090</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration> EOF
4.修改mapred-site.xml配置文件
操作节点:master
将master修改成你自己的主节点的主机名
作用 :配置MapReduce作业的运行参数。
mapreduce.framework.namemapreduce.jobhistory.addressmapreduce.jobhistory.webapp.address环境变量配置 :设置MapReduce作业运行时的环境变量,例如HADOOP_MAPRED_HOME。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 cat > /usr/local/hadoop/etc/hadoop/mapred-site.xml<<"EOF" <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> </configuration> EOF
5.修改yarn-site.xml文件
操作节点:master
将master修改成你自己的主节点的主机名
作用 :配置YARN(Yet Another Resource Negotiator)的参数。
yarn.resourcemanager.hostnameyarn.nodemanager.aux-services
1 2 3 4 5 6 7 8 9 10 11 12 cat > /usr/local/hadoop/etc/hadoop/yarn-site.xml<<"EOF" <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> EOF
将上述配置拷贝到slave
操作节点:master
1 2 3 4 5 6 7 cd /usr/local/hadoop/etc/hadoop/scp core-site.xml slave:/usr/local/hadoop/etc/hadoop/ scp hdfs-site.xml slave:/usr/local/hadoop/etc/hadoop/ scp mapred-site.xml slave:/usr/local/hadoop/etc/hadoop/ scp workers slave:/usr/local/hadoop/etc/hadoop/ scp yarn-site.xml slave:/usr/local/hadoop/etc/hadoop/ cd
这里是不用输入密码,如果提示你要输入密码,说明你前面4.2的ssh免密没做好
修改环境变量拷贝到slave
操作节点:master
1 2 3 4 5 6 7 8 echo "export HDFS_NAMENODE_USER=root" >> /etc/profile echo "export HDFS_DATANODE_USER=root" >> /etc/profile echo "export HDFS_SECONDARYNAMENODE_USER=root" >> /etc/profile echo "export YARN_RESOURCEMANAGER_USER=root" >> /etc/profile echo "export YARN_NODEMANAGER_USER=root" >> /etc/profile source /etc/profile scp /etc/profile slave:/etc/profile source /etc/profile
修改hadoop环境配置文件
操作节点:master
并将配置文件拷贝到slave
1 2 echo "export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_371" >> /usr/local/hadoop/etc/hadoop/hadoop-env.shscp /usr/local/hadoop/etc/hadoop/hadoop-env.sh slave:/usr/local/hadoop/etc/hadoop/hadoop-env.sh
集群启动
操作节点:master
master初始化
启动hadoop
操作节点:master
启动的时候如果有这些没关系
启动historyserver
操作节点:master
1 mapred --daemon start historyserver
关闭用
1 mapred --daemon stop historyserver
查看进程
两个节点说运行的服务如下
1 2 3 4 5 6 7 8 9 10 11 root@master:~# jps 31364 ResourceManager 31140 SecondaryNameNode 30856 NameNode 32282 Jps 28046 JobHistoryServer root@slave:~# jps 6304 DataNode 6444 NodeManager 6605 Jps
访问hadoop页面
http://192.168.48.128:8088/
http://192.168.48.128:9870/
至此分布式hadoop集群构建成功
这时候就你要给你这两台机,打上hadoop集群部署成功的快照,以便你后期做项目不报错可以恢复
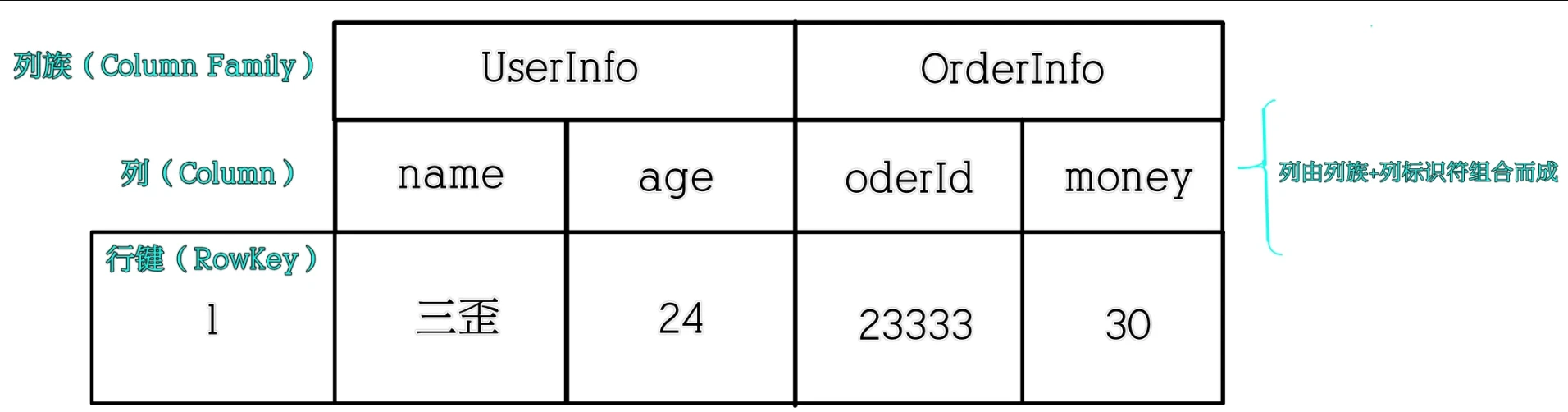
HBase
HBase 是一个面向列式存储的分布式数据库,其设计思想来源于 Google 的 BigTable 论文。HBase 底层存储基于 HDFS 实现,集群的管理基于 ZooKeeper 实现。HBase 良好的分布式架构设计为海量数据的快速存储、随机访问提供了可能,基于数据副本机制和分区机制可以轻松实现在线扩容、缩容和数据容灾,是大数据领域中 Key-Value 数据结构存储最常用的数据库方案。
本实验部署在伪分布机子上
安装
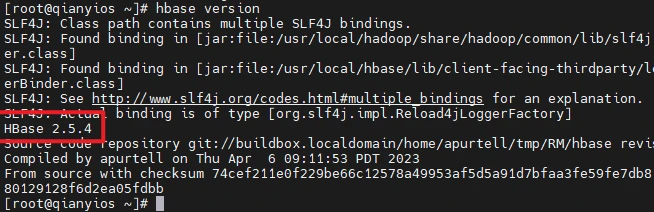
1 2 3 4 5 6 7 tar -xf /root/hadoop/hbase-2.5.4-bin.tar.gz -C /usr/local/ mv /usr/local/hbase-2.5.4 /usr/local/hbaseecho "export HBASE_HOME=/usr/local/hbase" >> /etc/profileecho "export PATH=\$PATH:\$HBASE_HOME/bin" >> /etc/profilesource /etc/profilesed -i "s/CLASSPATH=\${CLASSPATH}:\$JAVA_HOME\/lib\/tools.jar/CLASSPATH=\${CLASSPATH}:\$JAVA_HOME\/lib\/tools.jar:\/usr\/local\/hbase\/lib\/*/g" /usr/local/hbase/bin/hbase hbase version
HBase配置
文件里的qianyios要改成你的主机名,运行 HDFS NameNode 的主机名。
hbase.cluster.distributed
设置为 true 表示 HBase 以分布式模式运行。
如果设置为 false,HBase 将以单机模式运行(通常用于测试)。
HBASE_MANAGES_ZK=true
HBASE_MANAGES_ZK=true
表示 HBase 将启动并管理自己的嵌入式 ZooKeeper 实例。
这种模式通常用于单机环境或小型测试环境,简化了配置和管理。
HBASE_MANAGES_ZK=false
表示 HBase 不会启动自己的 ZooKeeper 实例,而是依赖外部独立的 ZooKeeper 集群。
这种模式适用于生产环境,推荐使用独立的 ZooKeeper 集群以提高稳定性和性能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 echo "export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_371" >> $HBASE_HOME /conf/hbase-env.shecho "export HBASE_CLASSPATH=/usr/local/hbase/conf" >> $HBASE_HOME /conf/hbase-env.shecho "export HBASE_MANAGES_ZK=true" >> $HBASE_HOME /conf/hbase-env.shecho "export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP=true" >> $HBASE_HOME /conf/hbase-env.shcat >$HBASE_HOME /conf/hbase-site.xml<<"EOF" <configuration> <property> <name>hbase.rootdir</name> <value>hdfs://qianyios:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true </value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false </value> </property> </configuration> EOF
启动hbase
1 2 start-all.sh start-hbase.sh
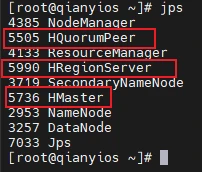
然后输入jps,有以下三个个就安装成功
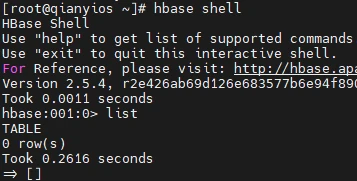
测试hbase
能运行没报错就行
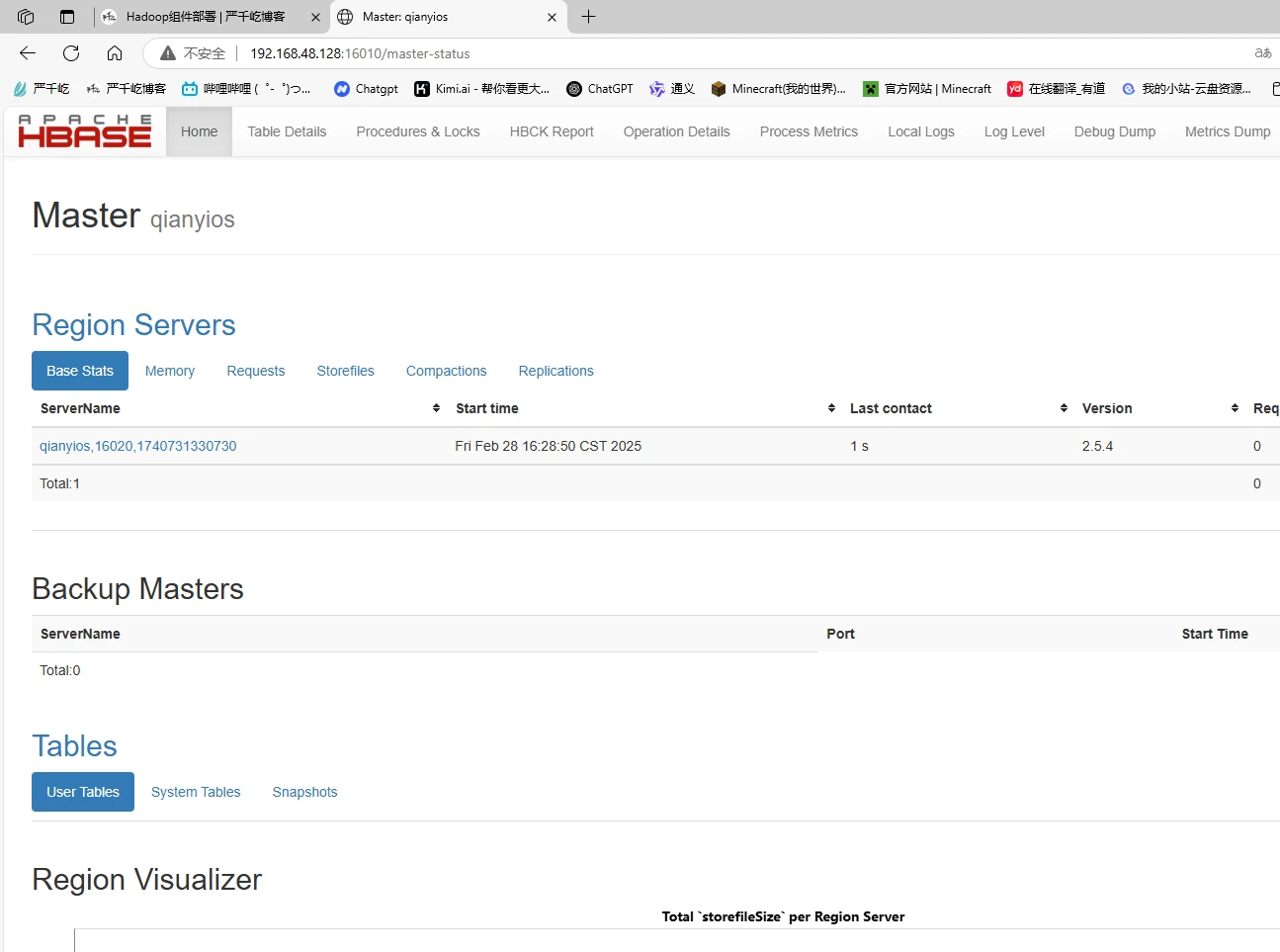
访问hbase网页
http://192.168.48.128:16010/
关机备份打快照
关机顺序
1 2 3 stop-hbase.sh stop-all.sh poweroff
开机顺序
1 2 start-all.sh start-hbase.sh
实例测试1
学号(S_No)
姓名(S_Name)
性别(S_Sex)
年龄(S_Age)
2015001
zhangsan
male
23
2015002
Mary
female
22
2015003
Lisi
male
24
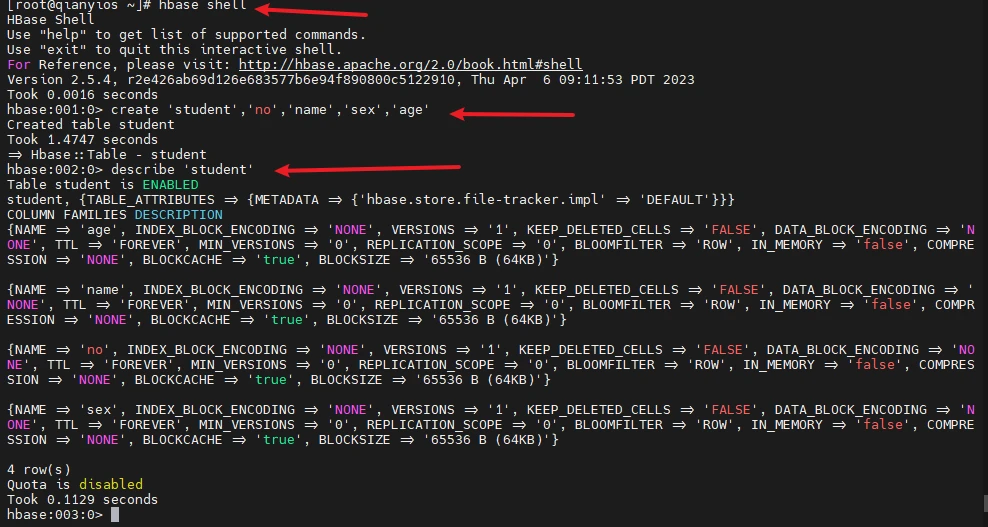
创建学生表
1 2 3 4 hbase shell create 'student' ,'no' ,'name' ,'sex' ,'age' describe 'student'
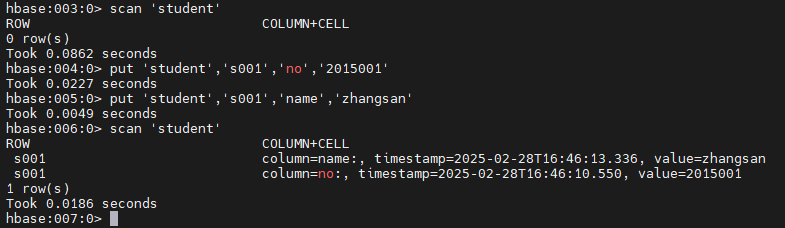
添加数据
s001为行键,行键可以自定义,但是要注意区别,按照前面的学生表,输入第一行s001的学生信息,我这里就简单输入一些信息,做例子用
1 2 3 4 5 scan 'student' put 'student' ,'s001' ,'no' ,'2015001' put 'student' ,'s001' ,'name' ,'zhangsan' scan 'student'
查看整行
查看单元格
1 get 'student','s001','name'
实例测试2
这是一个订单表
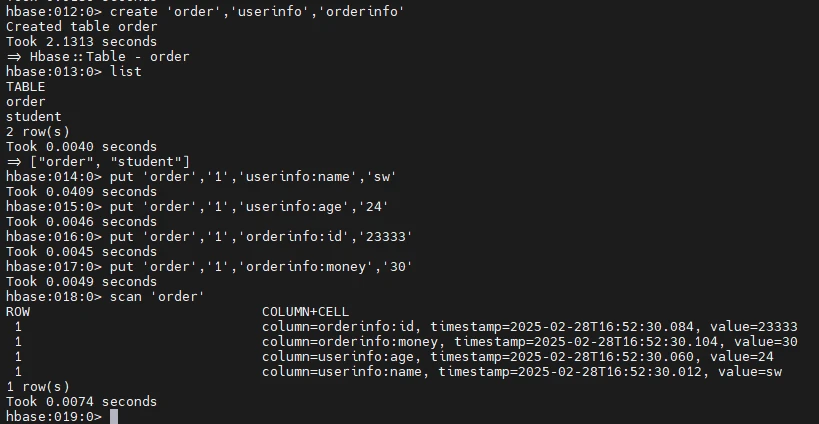
创建order表
创建一个order表,出现两列族userinfo,orderinfo
你看这次的行是1就和上个实例的s001,是不一样,都是可以自定义的
然后在列族下创建列userinfo:name,userinfo:age,orderinfo:id,orderinfo:money
在创建列的同时附带值
1 2 3 4 5 6 7 create 'order','userinfo','orderinfo' list put 'order','1','userinfo:name','sw' put 'order','1','userinfo:age','24' put 'order','1','orderinfo:id','23333' put 'order','1','orderinfo:money','30' scan 'order'
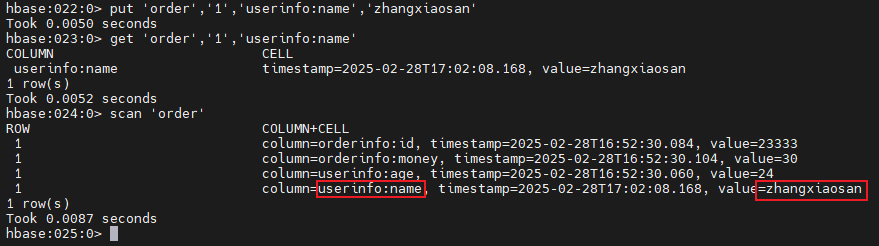
修改数据
1 2 3 put 'order','1','userinfo:name','zhangxiaosan' get 'order','1','userinfo:name' scan 'order'
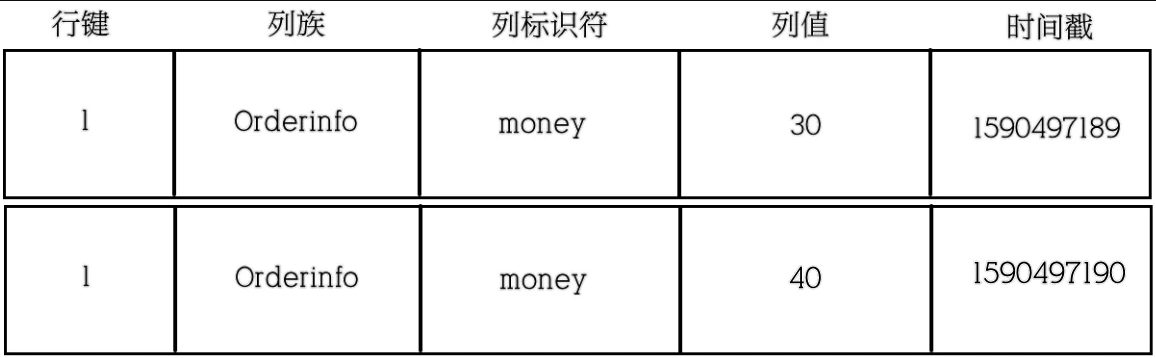
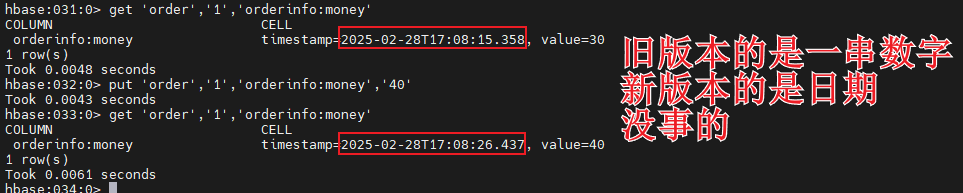
时间戳
数据添加到HBase的时候都会被记录一个时间戳,这个时间戳被我们当做一个版本。
当修改某一条的时候,本质上是往里边新增一条数据,记录的版本加一。
现在要把这条记录的值改为40,实际上就是多添加一条记录,在读的时候按照时间戳读最新的记录
1 2 3 get 'order','1','orderinfo:money' put 'order','1','orderinfo:money','40' get 'order','1','orderinfo:money'
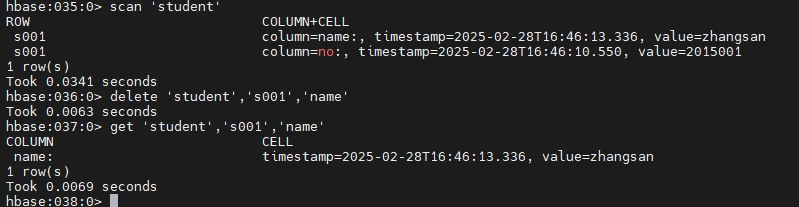
删除数据
name后一定要加个:
1 2 3 scan 'student' delete 'student','s001','name:' get 'student','s001','name'
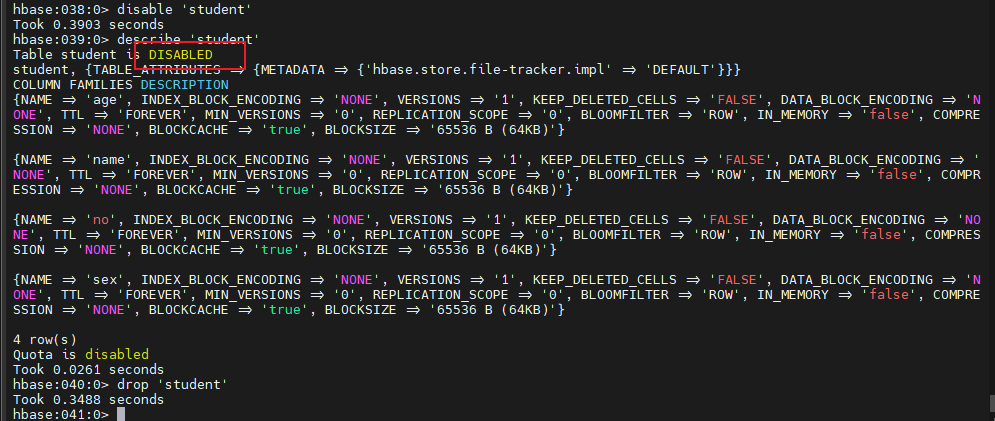
删除表
1 2 3 disable 'student' describe 'student' drop 'student'
Hive
hive 是一种底层封装了Hadoop 的数据仓库处理工具,使用类SQL 的hiveSQL 语言实现数据查询,所有hive 的数据都存储在Hadoop 兼容的文件系统、(例如,[Amazon S3](https://baike.baidu.com/item/Amazon S3/10809744)、HDFS)中。hive 在加载数据过程中不会对数据进行任何的修改,只是将数据移动到HDFS 中hive 设定的目录下,因此,hive 不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。
用户接口Client
用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是 Cli,Cli启动的时候,会同时启动一个 hive 副本。Client 是 hive 的客户端,用户连接至 hive Server。在启动 Client 模式的时候,需要指出 hive Server 所在节点,并且在该节点启动 hive Server。 WUI 是通过浏览器访问 hive。
元数据存储 Metastore
hive 将元数据存储在数据库中,如 mysql、derby。hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
驱动器:Driver 解释器、编译器、优化器、执行器
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
Hadoop
hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(不包含 * 的查询,比如 select * from tbl 不会生成 MapReduce 任务)。
安装hive
qianyios:3306这里要改成你的主机名
root是数据库的root用户
qianyios666是数据库密码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 tar -xf /root/hadoop/apache-hive-3.1.3-bin.tar.gz mv apache-hive-3.1.3-bin /usr/local/hiveecho "export HIVE_HOME=/usr/local/hive" >> /etc/profileecho "export PATH=\$HIVE_HOME/bin:\$PATH" >> /etc/profilesource /etc/profilecat >/usr/local/hive/conf/hive-site.xml<<"EOF" <?xml version="1.0" encoding="UTF-8" standalone="no" ?> <?xml-stylesheet type ="text/xsl" href="configuration.xsl" ?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://qianyios:3306/hive?createDatabaseIfNotExist=true &useSSL=false </value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>qianyios666</value> <description>password to use against metastore database</description> </property> <property> <name>hive.exec.mode.local.auto</name> <value>true </value> </property> </configuration> EOF
安装mysql
1 2 3 4 5 apt remove mariadb* -y apt install -y net-tools wget mysql-server systemctl enable --now mysql mysql_secure_installation
1 2 3 4 5 6 Press y|Y for Yes, any other key for No: no Remove anonymous users ?: yes Disallow root login remotely?: no Remove test database and access to it?: yes Reload privilege tables now?: yes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 mysql -uroot CREATE USER IF NOT EXISTS 'root' @'localhost' IDENTIFIED BY 'qianyios666' ; GRANT ALL PRIVILEGES ON *.* TO 'root' @'localhost' WITH GRANT OPTION; ALTER USER 'root' @'localhost' IDENTIFIED WITH mysql_native_password BY 'qianyios666' ; CREATE USER IF NOT EXISTS 'root' @'qianyios' IDENTIFIED BY 'qianyios666' ; GRANT ALL PRIVILEGES ON *.* TO 'root' @'qianyios' WITH GRANT OPTION; FLUSH PRIVILEGES; create database hive; exit sudo sed -i 's/^bind-address\s*=\s*127.0.0.1/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnfsudo sed -i 's/^mysqlx-bind-address\s*=\s*127.0.0.1/mysqlx-bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnfsystemctl restart mysql
启动hive
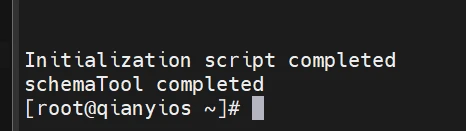
1 2 3 4 5 6 7 8 9 10 11 cd wget -P /root/hadoop/ https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-8.0.11.tar.gz tar -xf /root/hadoop/mysql-connector-java-8.0.11.tar.gz cp mysql-connector-java-8.0.11/mysql-connector-java-8.0.11.jar /usr/local/hive/lib/mv /usr/local/hive/lib/guava-19.0.jar{,.bak}cp /usr/local/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/hive/libstart-all.sh schematool -dbType mysql -initSchema hive
hive初始化有这个说明成功初始化如果失败,检查一下配置文件或者数据库
要退出就按两下ctrl+C
Hive数据类型
类型
描述
示例
TINYINT(tinyint)
一个字节(8位)有符号整数, -128~127
1
SMALLINT(smallint)
2字节(16位)有符号整数,-32768~32767
1
INT(int)
4字节(32位)有符号整数
1
BIGINT(bigint)
8字节(64位)有符号整数
1
FLOAT(float)
4字节(32位)单精度浮点数
1
DOUBLE(double)
8字节(64位)双精度浮点数
1
DECIMAL(decimal)
任意精度的带符号小数
1
BOOLEAN(boolean)
true/false
true/false
STRING(string)
字符串,变长
‘a’,‘b’,‘1’
VARCHAR(varchar)
变长字符串
‘a’
CHAR(char)
固定长度字符串
‘a’
BINANY(binany)
字节数组
无法表示
TIMESTAMP(timestamp)
时间戳,纳秒精度
1.22327E+11
DATE(date)
日期
‘2016-03-29’
hive的集合数据类型
类型
描述
示例
ARRAY
有序数组,字段的类型必须相同
Array(1,2)
MAP
一组无序的键值对,键的类型必须是原始数据类型,他的值可以是任何类型,同一个映射的键的类型必须相同,值得类型也必须相同
Map(‘a’,1)
STRUCT
一组命名的字段,字段类型可以不同
Struct(‘a’,1,2.0
UNION
UNION则类似于C语言中的UNION结构,在给定的任何一个时间点,UNION类型可以保存指定数据类型中的任意一种
基本命令
以下在hive数据仓库了运行,输入以下命令进入,可能启动有点慢
创建数据库和表
1 2 3 create database hive; use hive; create table usr(id int,name string,age int);
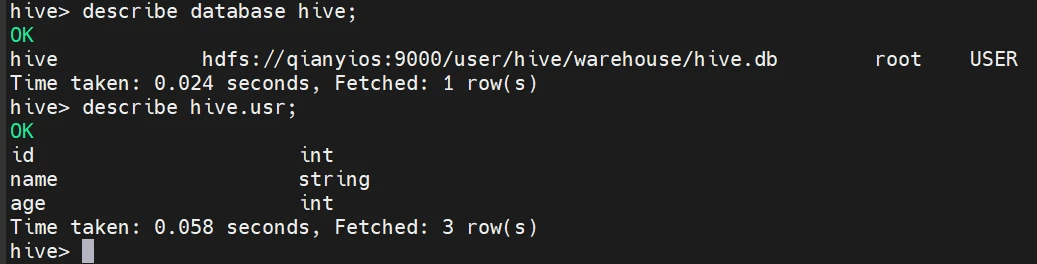
查看和描述数据库和表
1 2 3 4 5 show databases; show tables; USE hive; describe database hive; describe hive.usr;
向表中装载数据
1 2 3 4 5 6 7 8 insert into usr values(1,'sina' ,20); [root@qianyios555 ~]# echo "2,zhangsan,22" >> /opt/data hive> use hive; create table usr1(id int,name string,age int) row format delimited fields terminated by "," ; load data local inpath '/opt/data' overwrite into table usr1;
从hdfs中读取数据
1 2 3 4 5 6 #从linux读取数据 echo "3,lisi,25" > /opt/test.txt hdfs dfs -put /opt/test.txt / hive use hive; load data inpath 'hdfs://qianyios:9000/test.txt' overwrite into table usr1;
从别的表中读取数据
1 2 3 4 5 6 7 8 9 10 11 12 13 hive> select * from usr; OK 1 sina 20 hive> select * from usr1; OK 3 lisi 25 #读取usr1的id=3的数据到usr insert overwrite table usr select * from usr1 where id=3; hive> select * from usr; OK 3 lisi 25
查询表中数据
Hive实验:词频统计
在以上输入目录中添加多个文本文件,其中文件中包含单词:姓名学号,例如:qianyios555;
1 2 3 echo "hello1 qianyios555" > /opt/input/text1.txt echo "hello2 qianyios555" > /opt/input/text2.txt echo "hello3 qianyios555" > /opt/input/text3.txt
在Hive中创建表“docs”,并把输入目录的文件数据加载到该表中;
1 2 3 4 5 hive use hive; create table docs(line string); load data local inpath '/opt/input' overwrite into table docs; select * from docs;
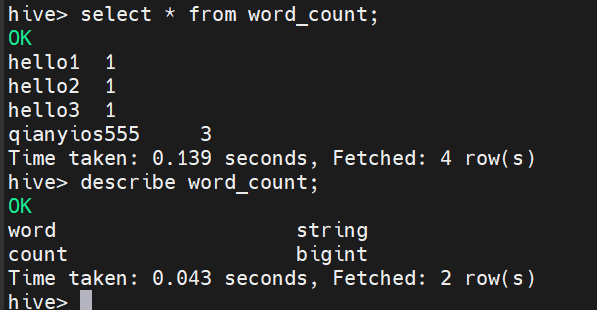
编写HiveQL语句对输入目录的文本进行词频统计,统计单词“姓名学号”出现的次数。
1 2 3 4 5 6 7 8 create table word_count as select word,count(1) as count from (select explode(split(line,' ')) as word from docs) w group by word order by word; select * from word_count; describe word_count;
千屹博客旗下的所有文章,是通过本人课堂学习和课外自学所精心整理的知识巨著









 微信
微信 支付宝
支付宝