Mysql高可用方案
MHA
介绍
技术有点老了,他只能安装在centos7类似于el7上,但是我发现他能安装在openeuler24.03上,所以本次实验就用openeuler去做mha的管理节点,你也可以用centos7
官方文档:github
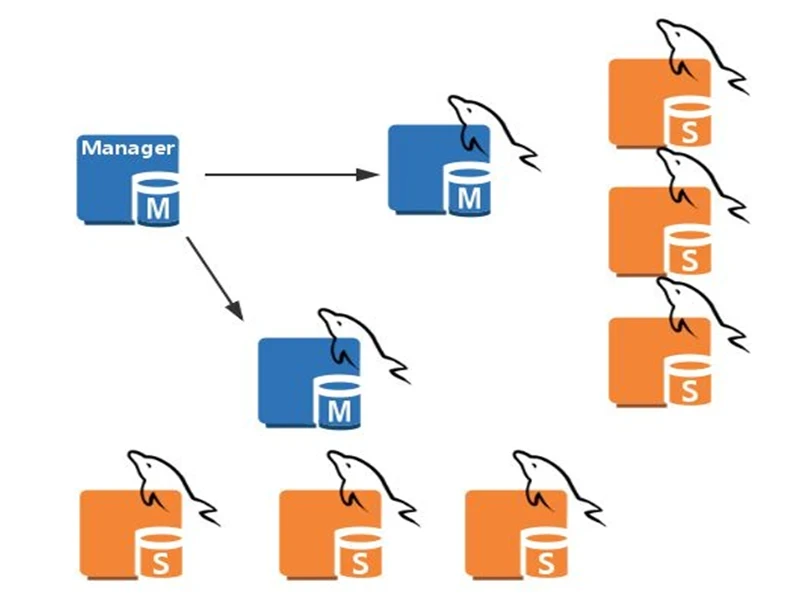
MHA集群架构
MHA工作原理
一、MHA 概述
MySQL MHA 是一套由 Percona 开源维护 的高可用性解决方案,主要用于自动监控和故障切换主从架构中的主节点(Master)。当主库出现故障时,MHA 能实现:
自动检测故障 选出最合适的 Slave 提升为新 Master 将其它从库指向新 Master 最小化数据丢失(秒级切换 + Binlog 恢复) 支持 VIP 漂移,保障业务连续性
二、MHA 故障切换流程图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [主库宕机] ↓ [Manager 触发 failover 脚本] ↓ [尝试拉取主库 binlog (mysqlbinlog)] ↓ [比较各 slave 的 relay log 差异] ↓ [选出最新、最完整的 slave] ↓ [提升为新的 master] ↓ [其他 slave 切换复制对象指向新的主节点] ↓ [VIP 漂移到新 master]
三、故障切换详细步骤
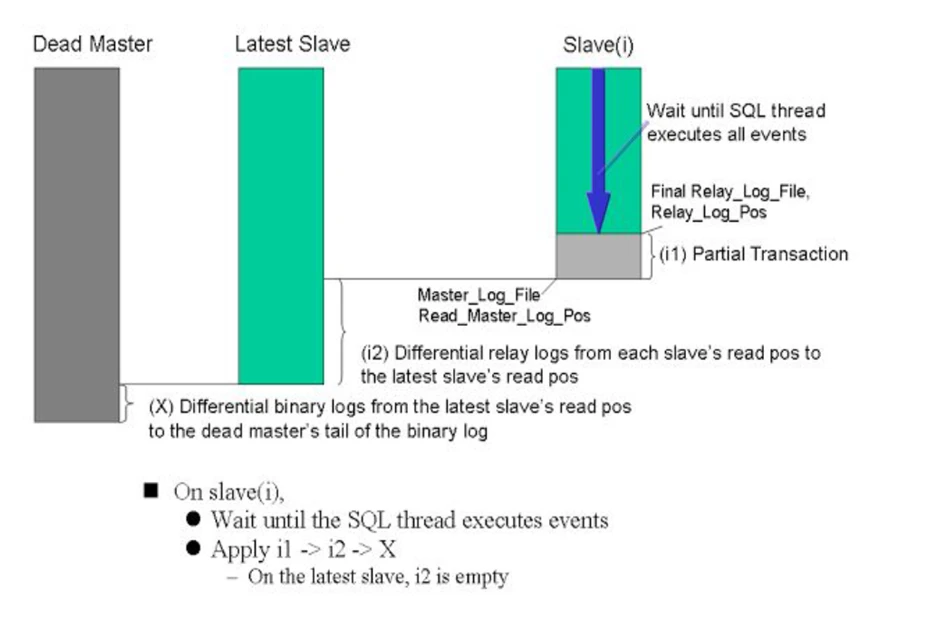
主库健康检查 SELECT 1 AS Value 监测 Master 健康状况。主库宕机识别 尝试拉取 Master 的 binlog mysqlbinlog 保存最新的二进制日志(Binlog Events)以减少数据丢失。识别最接近最新状态的 Slave 应用差异日志
如果主库可访问:应用 binlog 到其他从库
如果主库不可访问:通过对比 relay log 执行 apply_diff_relay_logs
选出新主库 其余从库切换复制对象 配置漂移
VIP 漂移到新的主库
应用层无感切换,继续写入数据
旧 Master 剔除集群 app1.cnf 中移除故障主库配置(如 masterha_conf_host)MHA 自行退出 masterha_manager 自动退出,需手动修复环境后再启动。
四、新主库选举逻辑
若设置了 candidate_master=1,优先考虑该从库。
若某个从库落后主库超过 100MB relay log,即使是候选,也会被跳过(除非设置 check_repl_delay=0)。
若多个从库数据一致,则选择配置文件中排在最前的。
若有差异,选出数据最接近 Master 的那个。
五、数据恢复机制
情况
操作
脚本
主库 SSH 可用
保存并分发主库 binlog 到从库
save_binary_logs
主库 SSH 不可用
比较各个从库 relay log,提取差异并分发
apply_diff_relay_logs
六、MHA 的局限与注意事项
一次性机制 建议开启半同步复制 对数据一致性要求较高
MHA软件
MHA软件由两部分组成,Manager工具包和Node工具包
Manager工具包主要包括以下几个工具:
1 2 3 4 5 6 7 8 9 masterha_check_ssh 检查MHA的SSH配置状况 masterha_check_repl 检查MySQL复制状况 masterha_manger 启动MHA masterha_check_status 检测当前MHA运行状态 masterha_master_monitor 检测master是否宕机 masterha_master_switch 故障转移(自动或手动) masterha_conf_host 添加或删除配置的server信息 masterha_stop --conf=app1.cnf 停止MHA masterha_secondary_check 两个或多个网络线路检查MySQL主服务器的可用
Node工具包: 这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
1 2 3 4 save_binary_logs apply_diff_relay_logs filter_mysqlbinlog purge_relay_logs
MHA自定义扩展:
1 2 3 4 5 6 secondary_check_script master_ip_ailover_script shutdown_script report_script init_conf_load_script master_ip_online_change_script
MHA配置文件:
1 2 global配置,为各application提供默认配置,默认文件路径 /etc/masterha_default.cnf application配置:为每个主从复制集群
实战案例
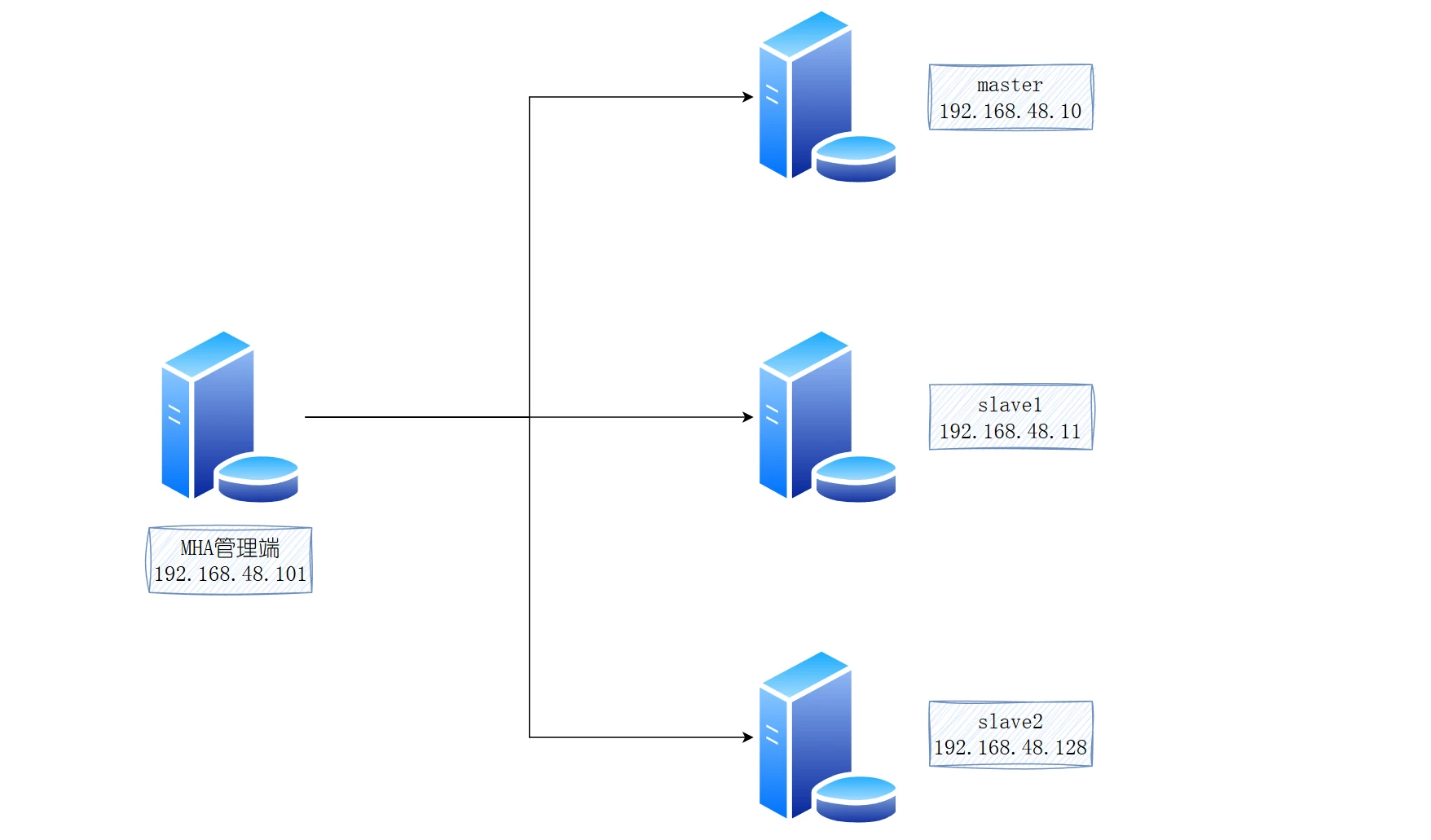
架构图
主机名
ip
内存
硬盘
MHA
192.168.48.101
3G
100G
master
192.168.48.10
3G
100G
slave1
192.168.48.11
3G
100G
slave2
192.168.48.128
3G
100G
安装mha软件
操作节点:[mha]
再次提醒 ,由于mha的软件没有更新,只支持el7,也就是centos7或者红帽7的系统,所以你自行斟酌,其次我发他是可以安装在openeuler24.03的,我打算试一下
github主页
mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
mha4mysql-node-0.58-0.el7.centos.noarch.rpm
自行下载这两个软件,上传到/root下
1 2 3 4 5 6 7 8 9 10 [root@MHA ~]# cat /etc/os-release NAME="openEuler" VERSION="24.03 (LTS)" ID="openEuler" VERSION_ID="24.03" PRETTY_NAME="openEuler 24.03 (LTS)" ANSI_COLOR="0;31" yum install -y mha4mysql-node-0.58-0.el7.centos.noarch.rpm mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
操作节点:[剩下的所有节点,也就是主从节点]
除MHA管理节点之外,都安装node包
mha4mysql-node-0.58-0.el7.centos.noarch.rpm
自行下载这两个软件,上传到/root下
1 yum install -y mha4mysql-node-0.58-0.el7.centos.noarch.rpm
ok,其他节点安装成功
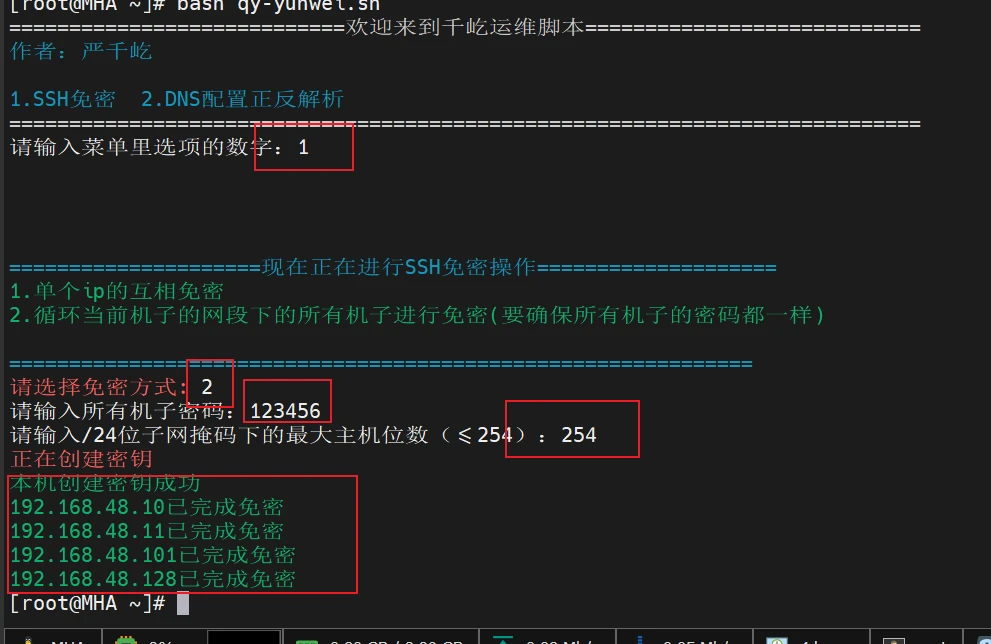
所有节点免密
操作节点:[MHA]
脚本方式
1 2 wget https://blog.qianyios.top/file/qy-yunwei.sh bash qy-yunwei.sh
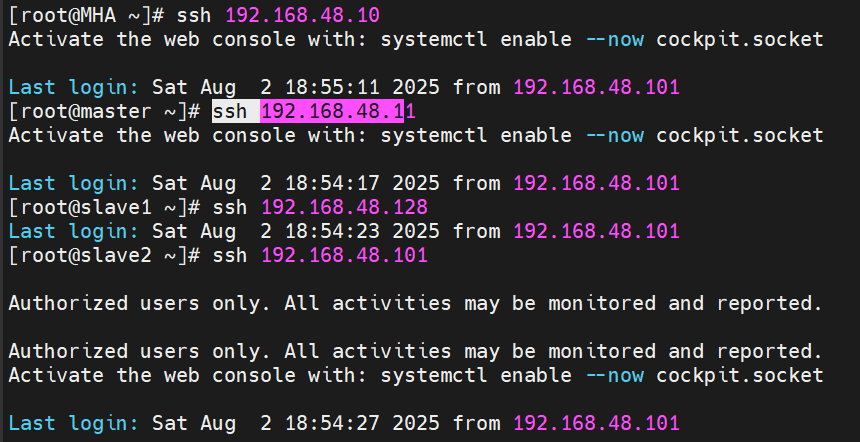
验证,互相登入
都不用密码
命令方式
1 2 3 4 5 6 ssh-keygen -t rsa -N "" -f ~/.ssh/id_rsa ssh-copy-id 127.0.0.1 yum install -y rsync rsync -av .ssh 192.168.48.10:/root/ rsync -av .ssh 192.168.48.11:/root/ rsync -av .ssh 192.168.48.128:/root/
在管理节点建立配置文件
操作节点:[MHA]
按自身需求进行修改
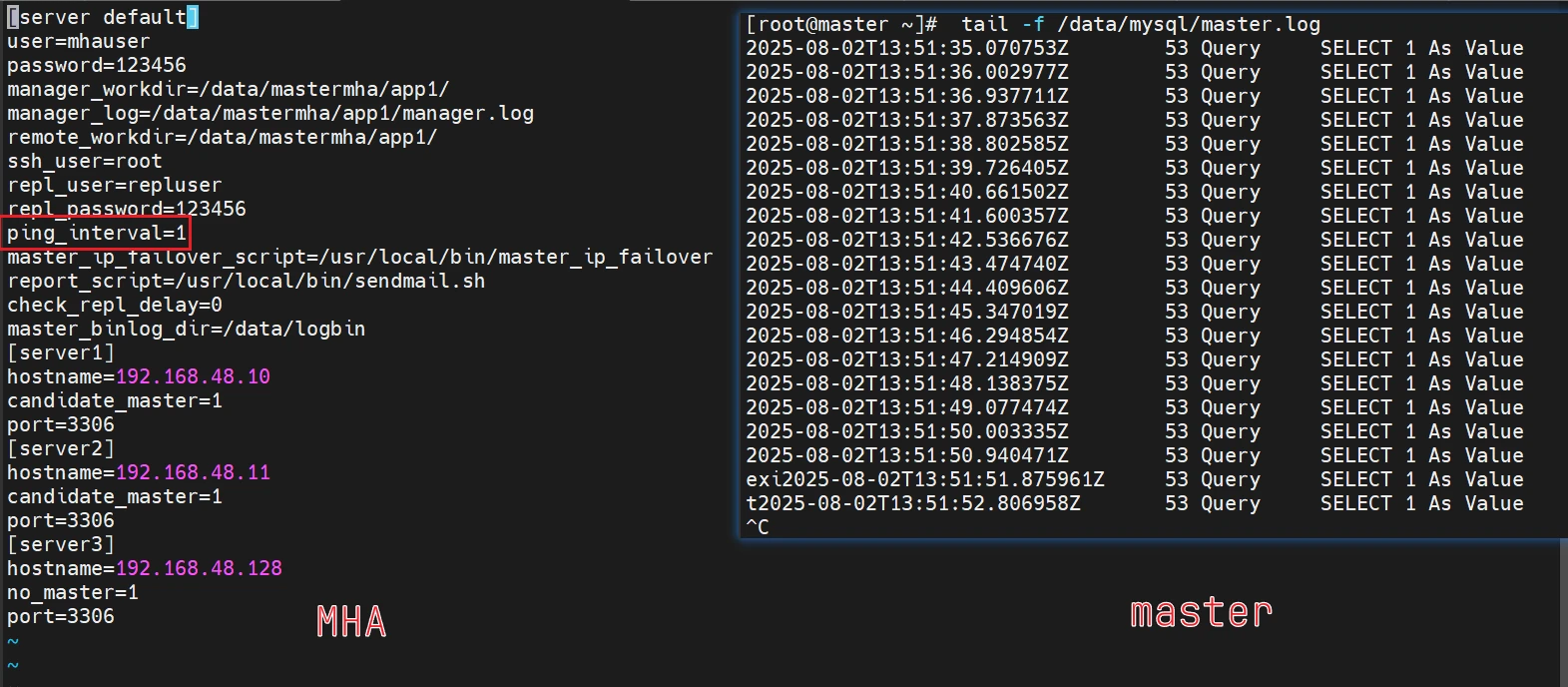
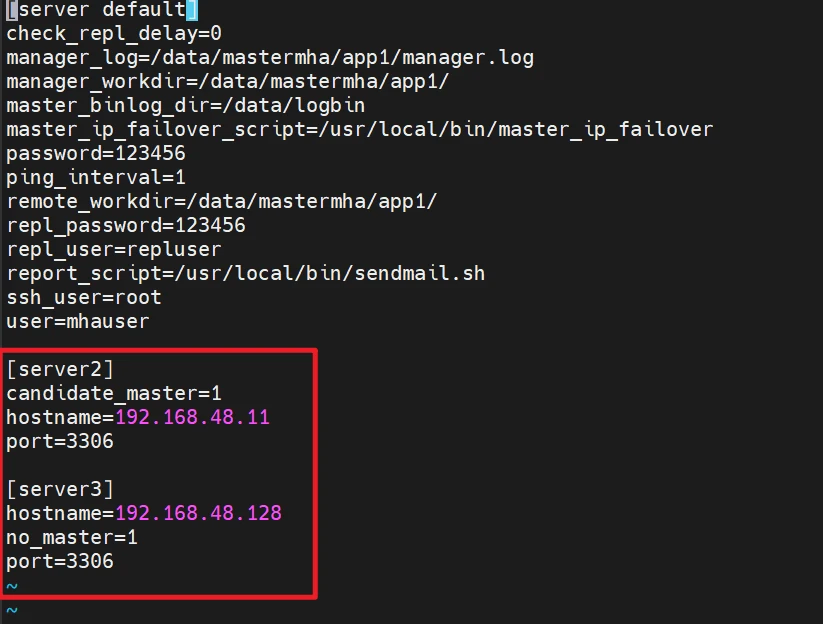
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 mkdir -p /etc/mastermha/ cat > /etc/mastermha/app1.cnf <<"EOF" [server default] user=mhauser password=123456 manager_workdir=/data/mastermha/app1/ manager_log=/data/mastermha/app1/manager.log remote_workdir=/data/mastermha/app1/ ssh_user=root repl_user=repluser repl_password=123456 ping_interval=1 master_ip_failover_script=/usr/local/bin/master_ip_failover report_script=/usr/local/bin/sendmail.sh check_repl_delay=0 master_binlog_dir=/data/logbin [server1] hostname=192.168.48.10 candidate_master=1 port=3306 [server2] hostname=192.168.48.11 candidate_master=1 port=3306 [server3] hostname=192.168.48.128 no_master=1 port=3306 EOF
配置解析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 [server default] user=mhauser password=123456 manager_workdir=/data/mastermha/app1/ manager_log=/data/mastermha/app1/manager.log remote_workdir=/data/mastermha/app1/ ssh_user=root repl_user=repluser repl_password=123456 ping_interval=1 master_ip_failover_script=/usr/local/bin/master_ip_failover report_script=/usr/local/bin/sendmail.sh check_repl_delay=0 master_binlog_dir=/data/logbin/ [server1] hostname=192.168.48.10 candidate_master=1 port=3306 [server2] hostname=192.168.48.11 candidate_master=1 port=3306 [server3] hostname=192.168.48.128 port=3306
说明: 主库宕机谁来接管新的master
相关脚本
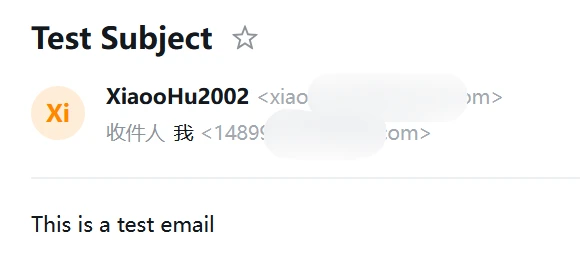
告警邮件
操作节点:[MHA]
1 2 3 4 5 6 7 8 9 10 yum install -y mailx cat <<EOT >> /etc/mail.rc set from=xiaoohxxxxx.com set smtp=smtp.163.com set smtp-auth-user=xiaooxxxxx3.com set smtp-auth-password=WXxxxxxBJUYX EOT echo "This is a test email" | mail -s "Test Subject" 148xxxx067@qq.com
smtp-auth-password是各个右键服务的第三方授权码,不是你的邮箱密码,这个你就自己去研究研究
告警脚本
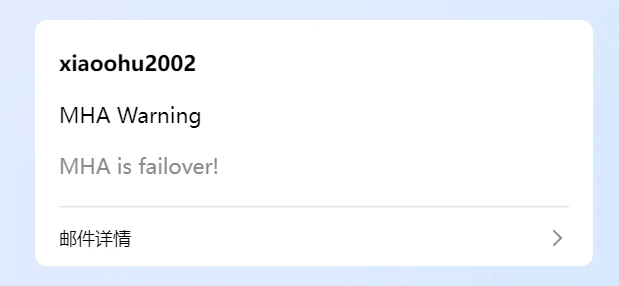
1 2 3 4 5 cat > /usr/local/bin/sendmail.sh << "EOF" echo "MHA is failover!" | mail -s "MHA Warning" 1489xxxxx.comEOF chmod +x /usr/local/bin/sendmail.sh
vip漂移脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 cat > /usr/local/bin/master_ip_failover <<"EOF" use strict; use warnings FATAL => 'all' ; use Getopt::Long; use MHA::DBHelper; my ( $command , $ssh_user , $orig_master_host , $orig_master_ip , $orig_master_port , $new_master_host , $new_master_ip , $new_master_port , $new_master_user , $new_master_password ); my $vip = '192.168.48.200/24' ; my $key = "qynet" ; my $ssh_start_vip = "/sbin/ifconfig ens160:$key $vip " ; my $ssh_stop_vip = "/sbin/ifconfig ens160:$key down" ; GetOptions( 'command=s' => \$command , 'ssh_user=s' => \$ssh_user , 'orig_master_host=s' => \$orig_master_host , 'orig_master_ip=s' => \$orig_master_ip , 'orig_master_port=i' => \$orig_master_port , 'new_master_host=s' => \$new_master_host , 'new_master_ip=s' => \$new_master_ip , 'new_master_port=i' => \$new_master_port , 'new_master_user=s' => \$new_master_user , 'new_master_password=s' => \$new_master_password , ); exit &main();sub main { if ( $command eq "stop" || $command eq "stopssh" ) { my $exit_code = 1; eval { $exit_code = 0; }; if ($@ ) { warn "Got Error: $@ \n" ; exit $exit_code ; } exit $exit_code ; } elsif ( $command eq "start" ) { my $exit_code = 10; eval { print "Enabling the VIP - $vip on the new master - $new_master_host \n" ; &start_vip(); &stop_vip(); $exit_code = 0; }; if ($@ ) { warn $@ ; exit $exit_code ; } exit $exit_code ; } elsif ( $command eq "status" ) { print "Checking the Status of the script.. OK \n" ; `ssh $ssh_user \@$orig_master_host \" $ssh_start_vip \"`; exit 0; } else { &usage(); exit 1; } } sub start_vip `ssh $ssh_user \@$new_master_host \" $ssh_start_vip \"`; } sub stop_vip `ssh $ssh_user \@$orig_master_host \" $ssh_stop_vip \"`; } sub usage { print "Usage: master_ip_failover --command=start|stop|stopssh|status -- orig_master_host=host --orig_master_ip=ip --orig_master_port=port -- new_master_host=host --new_master_ip=ip --new_master_port=port\n" ;} EOF chmod +x /usr/local/bin/master_ip_failover
实现一主二从复制
学到这里,主从复制我就不说过程了,具体可以看我的教程
一主多从 | 严千屹博客
然后创建前面配置文件写到的
user=mhauser # MHA管理用户
操作节点:[master]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 mysql -uroot -p123456 -e"create user mhauser@'192.168.48.%' identified by '123456';" mysql -uroot -p123456 -e"grant all on *.* to mhauser@'192.168.48.%';" ifconfig ens160:qynet 192.168.48.200/24 vim /etc/my.cnf server-id=10 log-bin=/data/logbin/qylog skip_name_resolve=1 general_log server-id=11 log-bin=/data/logbin/qylog skip_name_resolve=1 relay_log_purge=0#禁用自动清理中继日志文件 read_only=ON relay_log=/data/relaylog/relay-log relay_log_index=/data/relaylog/relay-log.index general_log server-id=128 log-bin=/data/logbin/qylog skip_name_resolve=1 relay_log_purge=0#禁用自动清理中继日志文件 read_only=ON relay_log=/data/relaylog/relay-log relay_log_index=/data/relaylog/relay-log.index general_log
在所有的从节点执行,不然后面检查mha的环境会报错
1 echo '[ -f /etc/profile ] && source /etc/profile' >> ~/.bashrc
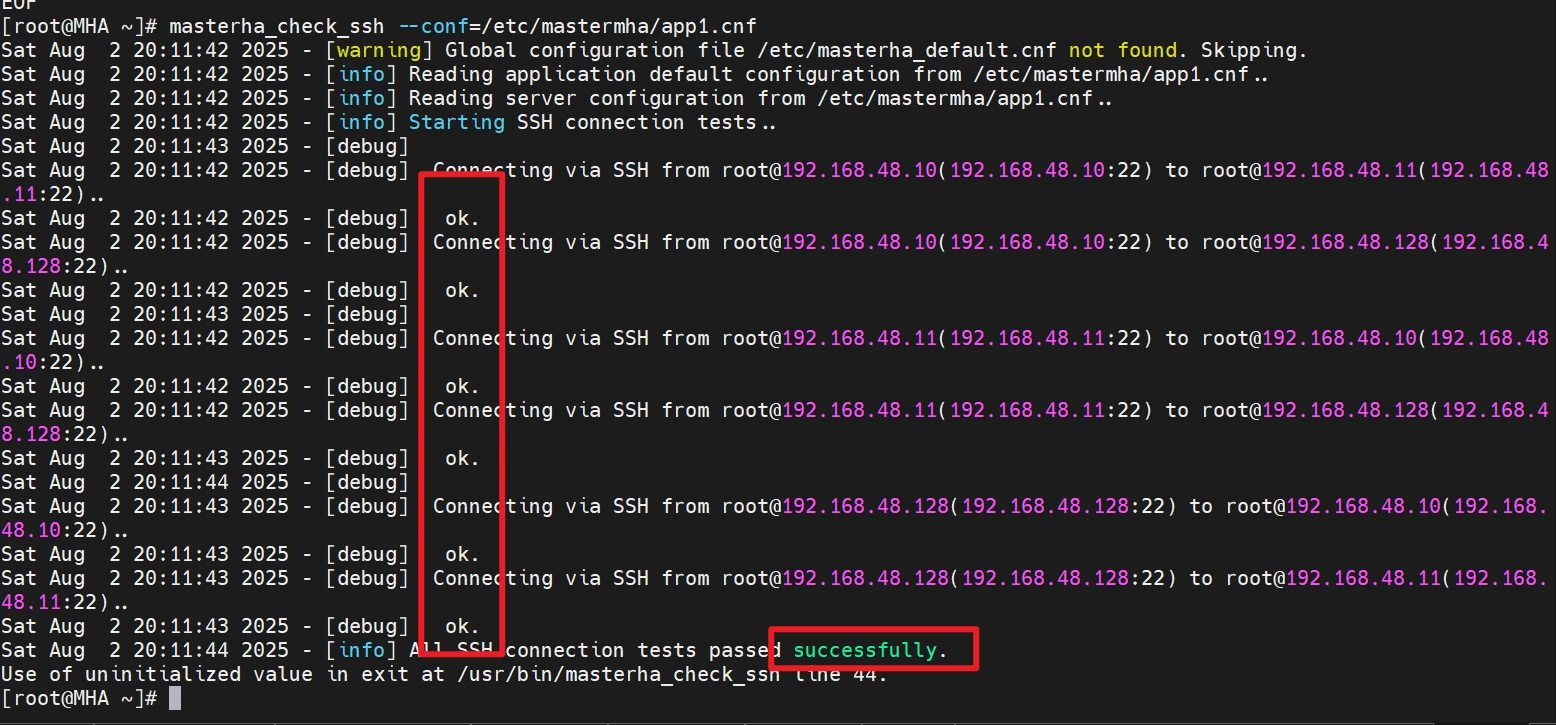
检查MHA的环境
操作节点:[mha]
1 2 sed -i '201s/.*/ my ($major, $minor) = ($str =~ m\/(\\d+)\/g); $major ||= 0; $minor ||= 0; my $result = sprintf("%03d%03d", $major, $minor);/' /usr/share/perl5/vendor_perl/MHA/NodeUtil.pm
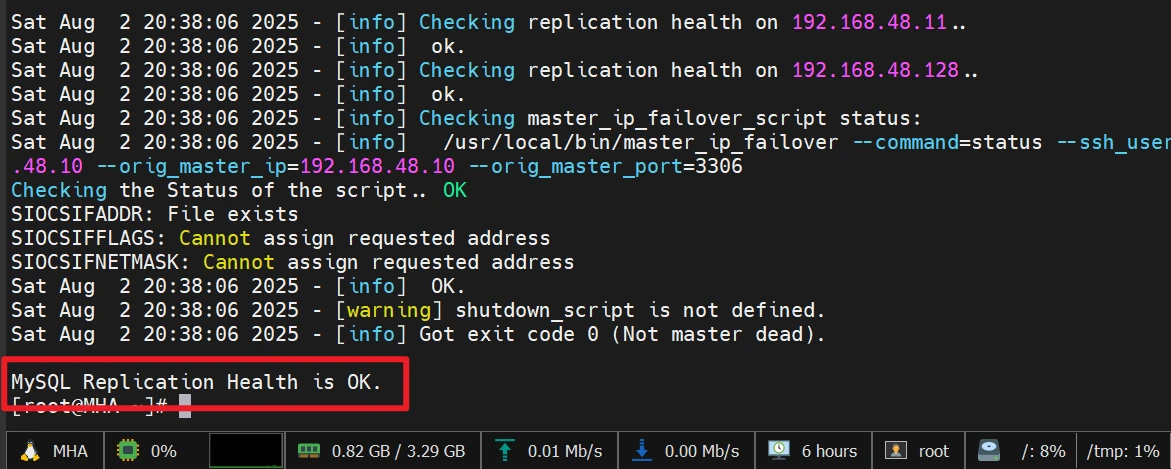
1 2 3 masterha_check_ssh --conf=/etc/mastermha/app1.cnf masterha_check_repl --conf=/etc/mastermha/app1.cnf
第一条目录的结果
第二条的结果
1 2 3 [root@MHA ~]# masterha_check_status --conf=/etc/mastermha/app1.cnf app1 is stopped(2:NOT_RUNNING).
运行MHA
手动启动 MHA 的故障转移(Failover)管理器 的,用于高可用场景下的主从数据库切换。运行后它会做这些事:
检查主库是否存活;
如果主库挂了,自动选举新主库;
重新配置复制结构;
处理 VIP 等附属逻辑;
任务完成后就退出了(这就是“一次性”的意思)✅。
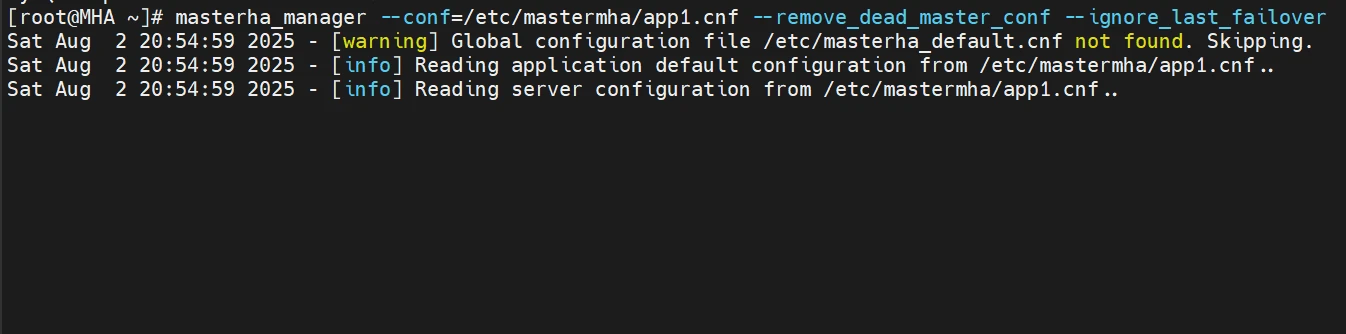
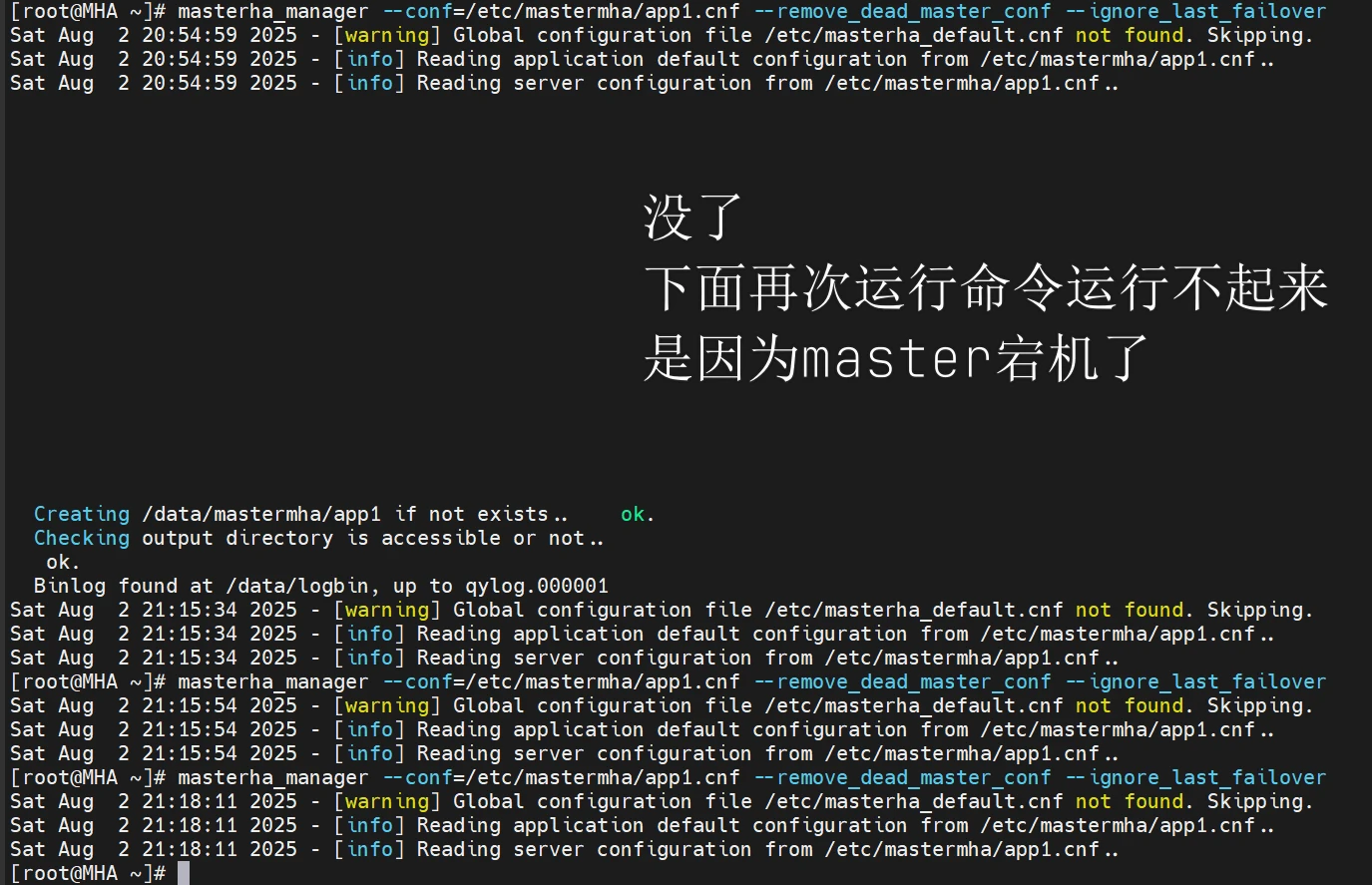
1 2 3 4 5 6 7 8 9 10 11 12 13 14 nohup masterha_manager --conf=/etc/mastermha/app1.cnf --remove_dead_master_conf --ignore_last_failover &> /dev/null masterha_manager --conf=/etc/mastermha/app1.cnf --remove_dead_master_conf --ignore_last_failover [root@mha-master ~]# masterha_stop --conf=/etc/mastermha/app1.cnf Stopped app1 successfully. masterha_check_status --conf=/etc/mastermha/app1.cnf
在手动启动之后,因为他是前台运行的,他就会是这样,没事的
去master查看健康性
1 2 3 4 5 tail -f /var/lib/mysql/[主机名].log tail -f [mysql的数据目录,不是安装目录哈]/[主机名].log
模拟高可用实验
在前面的mha配置文件里不是配置了
master1和slave1这两个可以成为候选主节点吗,现在我模拟让master关闭mysqld模拟宕机的操作,注意MHA前台要启动哦,不然没办法看到信息,测试环境我就用了手动启动的
好吧本来说可以在前台看到MHA变化的信息,看不到
但是实验还是成功的
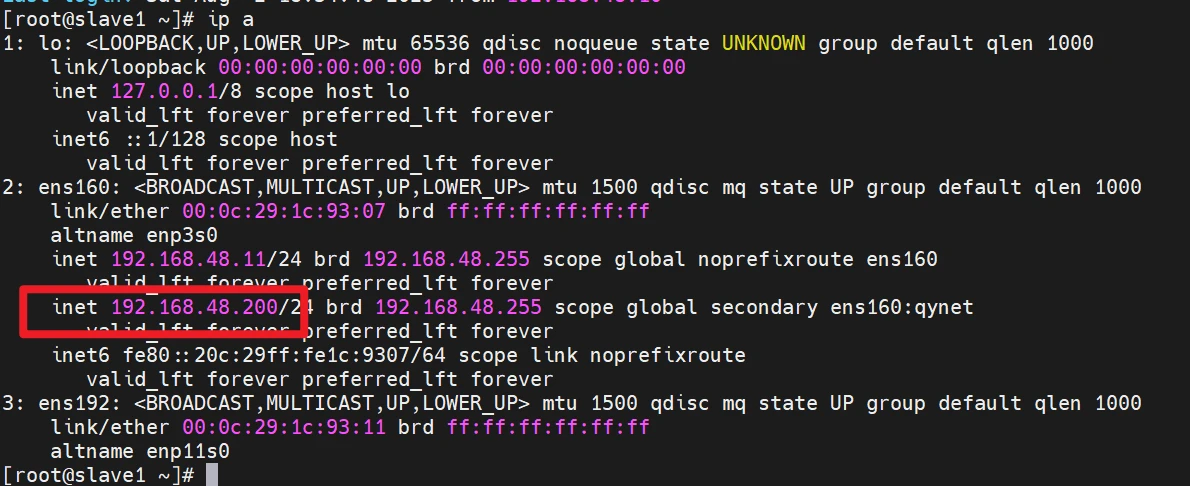
master的vip已经漂移过来了了
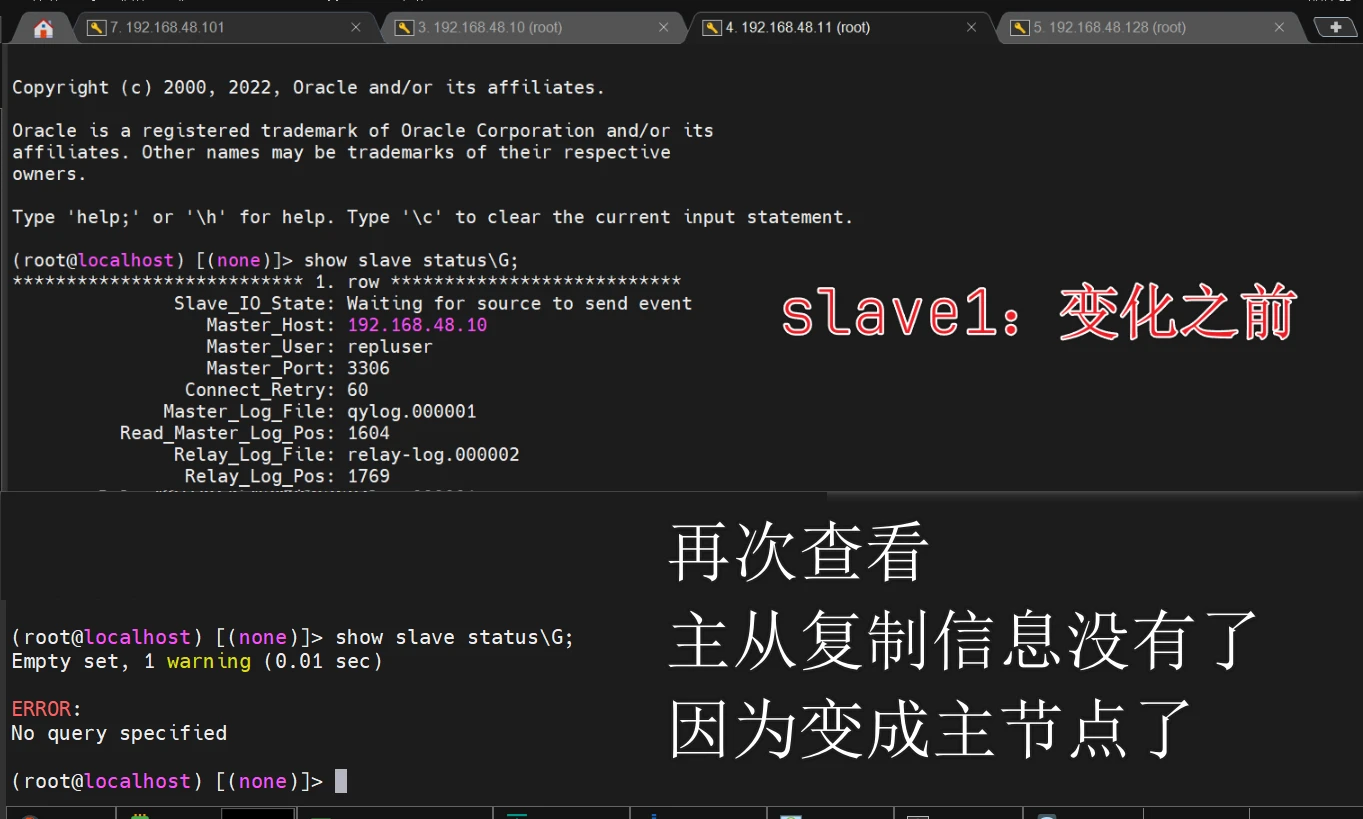
slave1已经变成主节点
虽然my.cnf配置了只读属性,但是slave1变成主节点之后,只读属性会关闭,不管配置文件是否开启,他的只读属性就会关闭
并且收到邮件了
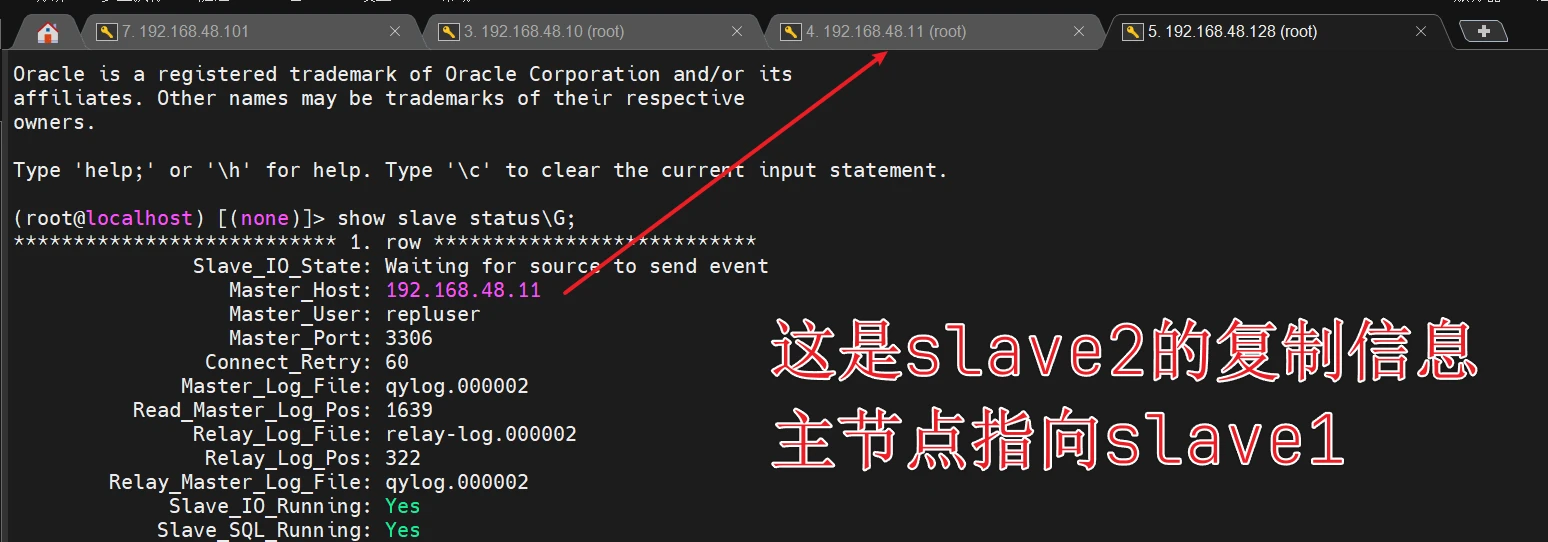
查看slave2的状态
最最最重要的是
/etc/mastermha/app1.cnf MHA的配置文件里的master的信息被删掉了
接着把master的mysql开起来
就有问题了
vip没有漂移回来,且master1没有变成从节点(没有复制信息),也不是主节点,当我尝试把slave1(之前变成主节点的机子),给他模拟宕机之后,ip也没漂回到master,且slave1的主从复制信息也没有回来
所以他就有一个短处
MHA是一次性的高可用性解决方案,Manager会自动退出
因为是主节点宕机后,MHA 自动将 slave1 提升为了新的主库。为什么会选它?可以回看文章开头的流程。
观众:博主大傻逼,还为啥会选他,你配置文件就两个机子成为了候选节点,不是他是谁
确实哈哈哈!不过要提醒一点:如果多个从库都配置为了候选主节点(candidate_master=1),MHA 就会进入完整的对比流程,比较各个候选 slave 的中继日志(relay log)和 主节点binlog应用位置,谁的数据最全就选谁作为新的主库。
而我这个实验中,只有一个 slave 被设定为候选主库,所以没体现出对比和选举的过程。但你得知道原理是那样的哈!
言归正传,怎么恢复之前的状态呢
把slave1的vip删除
1 ip a del 192.168.48.200/24 dev ens160:qynet
在master重新运行
1 ip a a 192.168.48.200/24 dev ens160:qynet
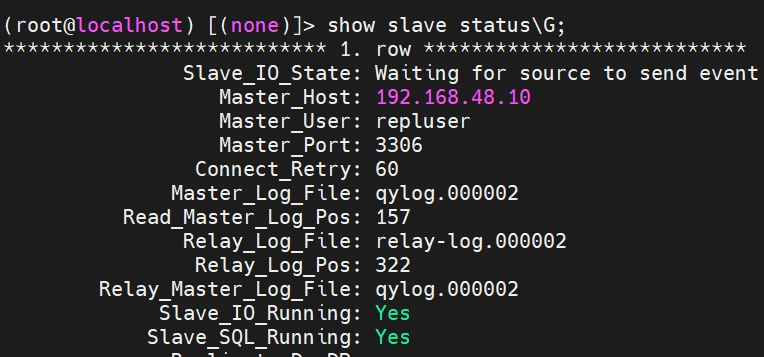
在slave1恢复主从复制连接
1.在master查看二进制文件的位置
1 2 3 4 5 6 7 8 9 show master logs; (root@localhost) [(none)]> show master logs; +--------------+-----------+-----------+ | Log_name | File_size | Encrypted | +--------------+-----------+-----------+ | qylog.000001 | 1627 | No | | qylog.000002 | 157 | No | +--------------+-----------+-----------+ 2 rows in set (0.01 sec)
2.slave1执行复制链接(要改为qylog.000002 起始位置157)
1 2 3 4 5 6 7 8 9 10 11 CHANGE MASTER TO MASTER_HOST='192.168.48.10' , MASTER_USER='repluser' , MASTER_PASSWORD='123456' , MASTER_LOG_FILE='qylog.000002' , MASTER_LOG_POS=157, get_master_public_key=1; start slave; show slave status\G;
slave2的主从复制连接也要重新设置
这里是,也要进行一次,主节点的全部备份到slave2进行还原一次,为什么因为他除了少了主节点的备份,也少了slave1的一些备份,你可以看文章最开头的架构图,阶梯状的,假设slave2也是候选节点,那选了slave1没选slave2,那不就是说明,slave2的同步的信息不够全嘛,所以也要进行一次重新备份,这里我也省略了。你知道要备份就行
1 2 3 4 5 6 7 8 9 10 11 stop slave; reset slave all; CHANGE MASTER TO MASTER_HOST='192.168.48.10' , MASTER_USER='repluser' , MASTER_PASSWORD='123456' , MASTER_LOG_FILE='qylog.000002' , MASTER_LOG_POS=157, get_master_public_key=1; start slave; show slave status\G;
在MHA节点重新配置/etc/mastermha/app1.cnf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 mkdir -p /etc/mastermha/ cat > /etc/mastermha/app1.cnf <<"EOF" [server default] user=mhauser password=123456 manager_workdir=/data/mastermha/app1/ manager_log=/data/mastermha/app1/manager.log remote_workdir=/data/mastermha/app1/ ssh_user=root repl_user=repluser repl_password=123456 ping_interval=1 master_ip_failover_script=/usr/local/bin/master_ip_failover report_script=/usr/local/bin/sendmail.sh check_repl_delay=0 master_binlog_dir=/data/logbin [server1] hostname=192.168.48.10 candidate_master=1 port=3306 [server2] hostname=192.168.48.11 candidate_master=1 port=3306 [server3] hostname=192.168.48.128 no_master=1 port=3306 EOF
1 2 3 4 5 masterha_check_ssh --conf=/etc/mastermha/app1.cnf masterha_check_repl --conf=/etc/mastermha/app1.cnf masterha_manager --conf=/etc/mastermha/app1.cnf --remove_dead_master_conf --ignore_last_failover
Percona XtraDB Cluster
介绍
✅Galera Cluster 简介
多主架构(Multi-Master) :任意节点都可读写,数据一致。同步复制 :事务需全节点确认,解决主从延迟。并发复制 :节点 apply 阶段可并行处理事务。自动节点克隆 :新节点可自动拉取数据同步。高可用性 :支持热插拔与故障快速切换。对应用透明 :无需对应用层做适配。
适用场景:高一致性要求、高可用、读写混合负载。
⚠️Galera Cluster 局限
性能受最慢节点影响(全局验证机制)。
新节点加入或数据落后时需全量同步(SST)。
仅支持 InnoDB 存储引擎。
🔧核心组件
galera-3:复制库WSREP:Write Set Replication,MySQL 扩展
📦 主流实现
Percona XtraDB Cluster (PXC) MariaDB Galera Cluster
最少部署3个节点 ,不可安装独立 mysql-server 或 mariadb-server
🔌 PXC 工作原理 & 架构
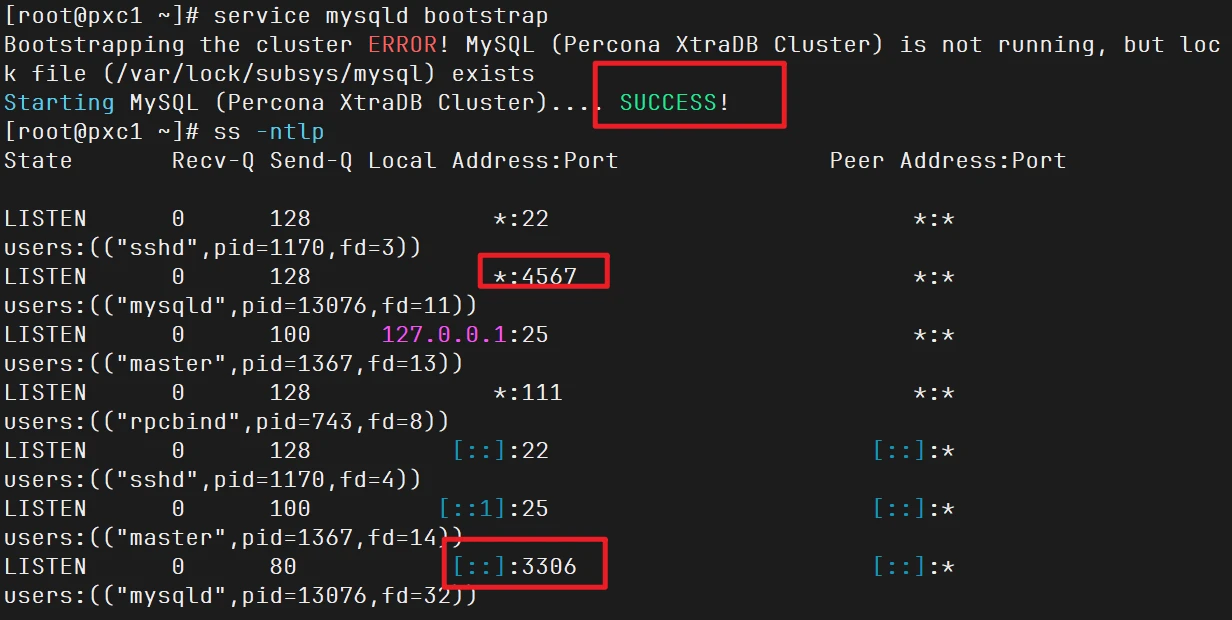
常用端口 :
3306:MySQL服务4444:SST传输4567:组通信4568:IST传输
节点状态流转 :open → primary → joiner → joined → synced数据同步方式 :
SST (全量):xtrabackup、rsync、mysqldumpIST (增量):xtrabackup(需 GCache 支持)
open
含义 :节点进程已启动,但尚未加入 Galera 集群。状态特点 :
MySQL 服务已启动;
节点还没建立与集群其他成员的通信连接;
Galera 还未初始化(如 wsrep_ready=OFF)。
👑 2. primary
含义 :节点成为主分区(Primary Component)的一部分。状态特点 :
处于健康的集群分区中;
可以对外提供读写服务;
多数节点(quorum)在线才能形成 primary;
若失去多数节点,将转为 non-primary,停止服务。
🚀 3. joiner
含义 :新节点开始加入集群,等待接收初始数据。状态特点 :
通信通道已建立;
正在准备 SST 或 IST;
此阶段节点不能提供服务;
表示“我要加入,请给我数据”。
🔗 4. joined
含义 :初始数据传输完成,但尚未完成状态一致同步。状态特点 :
数据已经拉取完毕;
正在进行数据一致性校验;
准备进入同步阶段。
✅ 5. synced
含义 :节点完成所有同步操作,正式加入集群。状态特点 :
数据与其他节点一致;
可以正常读写;
Galera 复制机制 fully ready;
wsrep_local_state_comment = Synced。
🧠 关键模块:GCache
缓存最近的写集用于 IST 增量同步建议配置 :
gcache.size = 2G~4Ggcache.mem_size:适当加大提升性能gcache.page_size:磁盘写集页大小
📚 参考文档
centos7二进制部署pxc5.7
架构图
所有系统都是centos7
主机名
ip
内存
硬盘
pxc1
192.168.48.10
3G
100G
pxc2
192.168.48.11
3G
100G
pxc3
192.168.48.12
3G
100G
pxc4
192.168.48.13
3G
100G
关闭防火墙和SELinux,保证时间同步,自己改主机名
注意:如果已经安装MySQL,必须卸载
必备资源
操作节点:[所有节点]
这是本次实验会用到的资源,请你提前下载好,上传到每个节点的/root下,因为我现在是用的是root用户
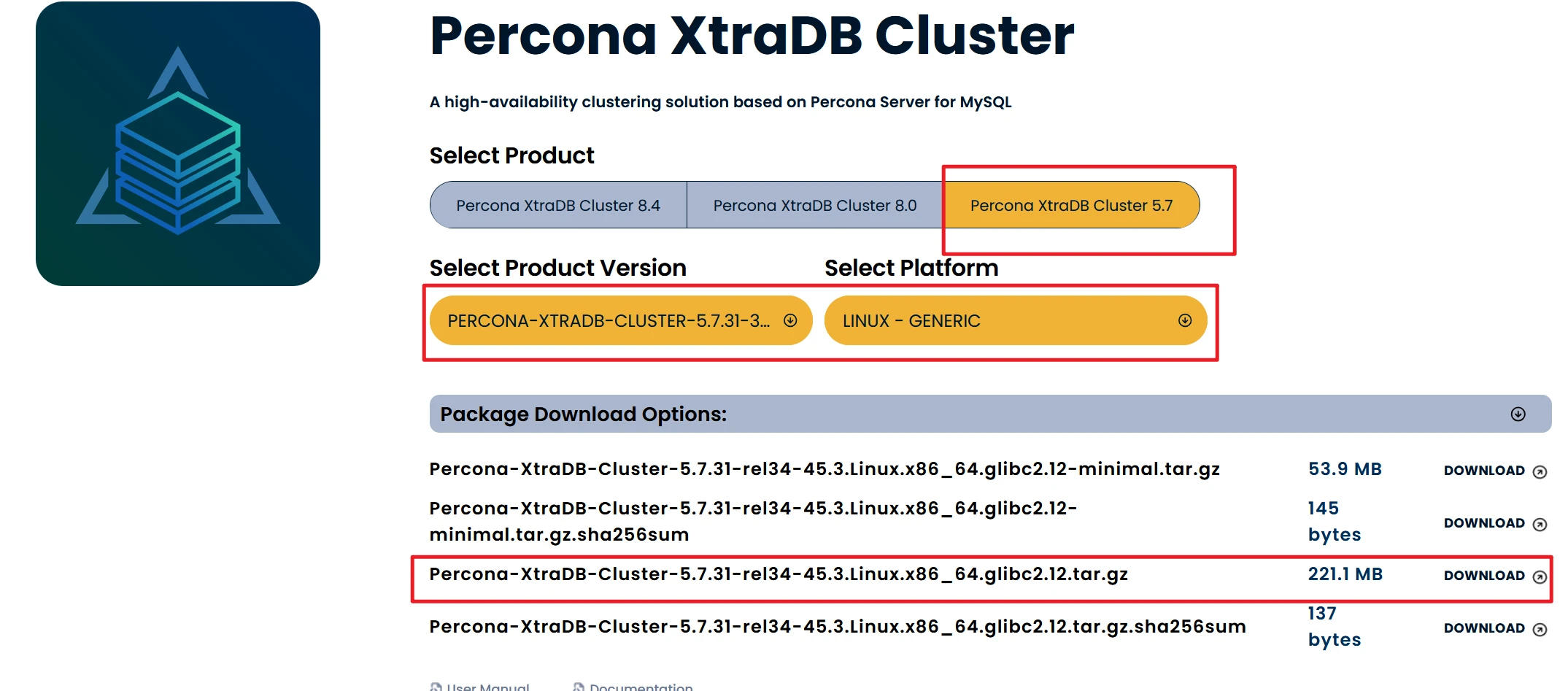
1.Percona XtraDB Cluster:
官网下载:Percona-XtraDB-Cluster-5.7.31-rel34-45.3.Linux.x86_64.glibc2.12.tar.gz
本站下载:Percona-XtraDB-Cluster-5.7.31-rel34-45.3.Linux.x86_64.glibc2.12.tar.gz
本站下载的包,那个名字可能会乱码,你自己改一下和文件名一模一样
2.xtrabackup
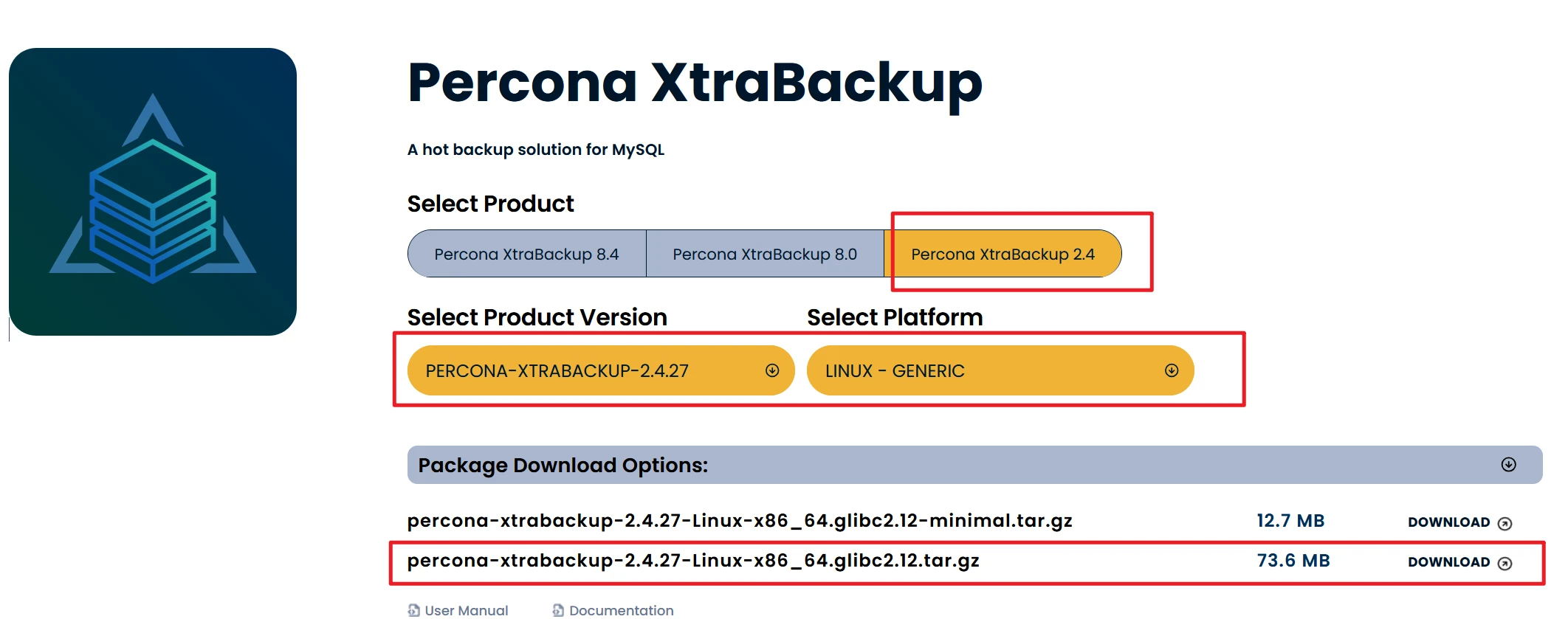
官网下载:percona-xtrabackup-2.4.27-Linux-x86_64.glibc2.12.tar.gz
本站下载:percona-xtrabackup-2.4.27-Linux-x86_64.glibc2.12.tar.gz
本站下载的包,那个名字可能会乱码,你自己改一下和文件名一模一样
安装基本软件
操作节点:[所有节点]
1 yum install libgcrypt libgcrypt-devel socat openssl-devel libaio numactl-libs libev -y
安装xtrabackup
操作节点:[所有节点]
1 2 3 4 5 mkdir -p /usr/local/pxc_temptar -xzf percona-xtrabackup-2.4.27-Linux-x86_64.glibc2.12.tar.gz --strip-components=1 -C /usr/local/pxc_temp \cp -rf /usr/local/pxc_temp/bin/{xtrabackup,xbcloud,xbcloud_osenv,xbcrypt,xbstream,innobackupex} /usr/local/bin/ chmod +x /usr/local/bin/{xtrabackup,xbcloud,xbcloud_osenv,xbcrypt,xbstream,innobackupex}rm -rf /usr/local/pxc_temp
创建mysql用户
操作节点:[所有节点]
1 2 groupadd mysql useradd -r -g mysql -s /bin/false mysql
解压安装包到指定目录
操作节点:[所有节点]
1 2 3 4 pxc_packge=$(ls | grep -i "Percona-XtraDB-Cluster-5.7*" ) pxc_packge_filename=$(echo $pxc_packge | awk -F'.tar' '{print $1}' ) tar -xzf $pxc_packge mv $pxc_packge_filename /usr/local/pxc
创建最基本的文件
操作节点:[所有节点]
路径
说明
示例值
basedir安装目录
/usr/local/pxc
datadir数据目录
/usr/local/pxc/data
my.cnf自定义配置文件
/usr/local/pxc/my.cnf
mysqld.socksocket 文件路径
/tmp/mysql.sock(或 /usr/local/pxc/tmp/mysql.sock)
libgalera_smm.soGalera provider
/usr/local/pxc/lib/libgalera_smm.so
1 2 3 4 5 6 mkdir -p /usr/local/pxc/{data,logs,tmp}chown -R mysql:mysql /usr/local/pxcecho 'export PATH=/usr/local/pxc/bin:$PATH' > /etc/profile.d/pxc.sh chmod +x /etc/profile.d/pxc.sh source /etc/profile.d/pxc.sh
每个节点的配置文件
操作节点:[所有节点]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 cluster_nodes="192.168.48.10,192.168.48.11,192.168.48.12" sst_user="sstuser" sst_pass="123456" node_name=$(hostname) node_ip=$(ip route get 1 | awk '{print $7; exit}' ) server_id=${node_ip##*.} cat > /etc/my.cnf <<EOF [client] # 客户端配置段 # 指定客户端使用的本地 socket 文件路径 socket=/usr/local/pxc/tmp/mysql.sock [mysqld] # 服务端配置段 # 设置该节点的唯一 server-id(一般取 IP 的最后一段) server-id=$server_id # 指定数据库的数据文件存放目录 datadir=/usr/local/pxc/data # 指定服务端使用的 socket 文件路径 socket=/usr/local/pxc/tmp/mysql.sock # 指定错误日志文件路径 log-error=/usr/local/pxc/logs/mysqld.log # 指定进程 ID 文件路径 pid-file=/usr/local/pxc/data/mysqld.pid # 开启二进制日志并设置日志文件路径 log-bin=/usr/local/pxc/logs/qybin # 设置二进制日志格式为 ROW(PXC 要求) binlog_format=ROW # 指定 Galera 的共享库路径 wsrep_provider=/usr/local/pxc/lib/libgalera_smm.so # 指定集群中所有节点的 IP 列表 wsrep_cluster_address=gcomm://$cluster_nodes # 设置默认存储引擎为 InnoDB default_storage_engine=InnoDB # 设置用于复制的线程数 wsrep_slave_threads=8 # 启用冲突检测日志 wsrep_log_conflicts # 设置自增锁模式为 2(PXC 推荐) innodb_autoinc_lock_mode=2 # 当前节点用于集群通信的 IP 地址 wsrep_node_address=$node_ip # 设置集群名称,所有节点必须一致 wsrep_cluster_name=pxc-cluster # 设置当前节点的名称 wsrep_node_name=$node_name # 启用 PXC 严格模式,防止非事务引擎等问题 pxc_strict_mode=ENFORCING # 设置 SST(状态快照传输)的方法为 xtrabackup-v2 wsrep_sst_method=xtrabackup-v2 # 配置 SST 用户名和密码 wsrep_sst_auth="$sst_user:$sst_pass" EOF chown -R mysql:mysql /usr/local/pxc
注意:尽管Galera Cluster不再需要通过binlog的形式进行同步,但还是建议在配置文件中开启二进制日志功能,原因是后期如果有新节点需要加入,老节点通过SST全量传输的方式向新节点传输数据,很可能会拖垮集群性能,所以让新节点先通过binlog方式完成同步后再加入集群会是一种更好的选择
初始化mysql
操作节点:[所有节点]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 rm -rf /etc/init.d/mysqldcp /usr/local/pxc/support-files/mysql.server /etc/init.d/mysqldBASE_DIR="/usr/local/pxc" DATA_DIR="$BASE_DIR /data" LOGS_DIR="$BASE_DIR /logs" TMP_DIR="$BASE_DIR /tmp" PID_FILE="$DATA_DIR /mysqld.pid" INIT_SCRIPT="/etc/init.d/mysqld" sed -i \ -e "s|^basedir=.*|basedir=$BASE_DIR |" \ -e "s|^datadir=.*|datadir=$DATA_DIR |" \ -e "s|^mysqld_pid_file_path=.*|mysqld_pid_file_path=$PID_FILE |" \ "$INIT_SCRIPT " grep -q "^user=mysql" "$INIT_SCRIPT " || \ sed -i "/^app_name=/a user=mysql" "$INIT_SCRIPT " sed -i 's|^PATH="\(.*\)"|PATH="/usr/local/bin:\1"|' /etc/init.d/mysqld chmod +x "$INIT_SCRIPT " rm -rf /usr/local/pxc/data/*rm -rf /usr/local/pxc/logs/mysqld.logmysqld --initialize --user=mysql --datadir=/usr/local/pxc/data awk '/temporary password/{print $NF}' /usr/local/pxc/logs/mysqld.log
如果最后一天没有个随机字符出来,那你的mysql初始化就是失败的,你要检查一下了,自己看一下报错是啥
启动第一个节点
操作节点:[pxc1]
三个节点你选哪个都行
1 2 3 4 5 6 7 service mysqld bootstrap [root@pxc1 ~]# service mysqld bootstrap Bootstrapping the cluster ERROR! MySQL (Percona XtraDB Cluster) is not running, but lock file (/var/lock/subsys/mysql) exists Starting MySQL (Percona XtraDB Cluster).... SUCCESS! [root@pxc1 ~]# ss -ntlp
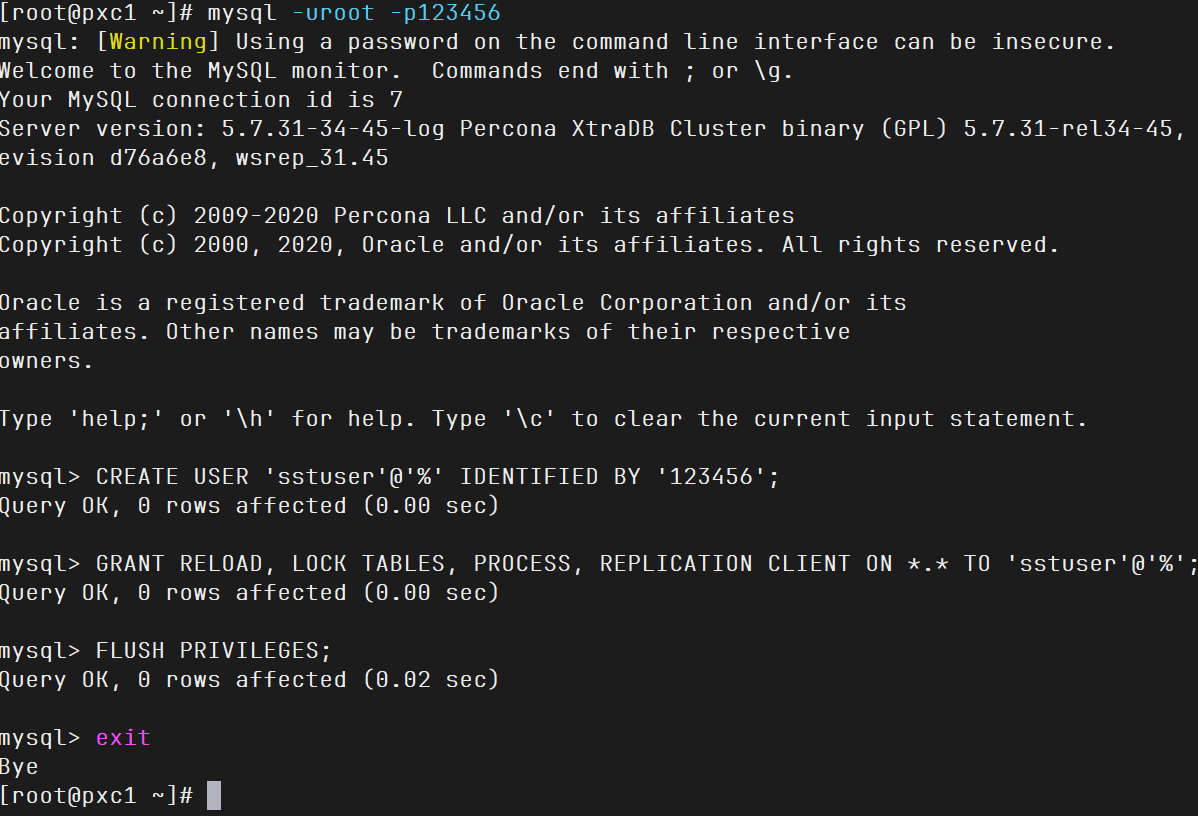
1 2 3 4 5 6 7 8 9 10 11 MYSQL_PASSWD="123456" MYSQL_OLD_PASSWD=$(awk '/temporary password/{print $NF}' /usr/local/pxc/logs/mysqld.log) mysql -uroot -p"$MYSQL_OLD_PASSWD " --connect-expired-password -e "ALTER USER 'root'@'localhost' IDENTIFIED BY '123456'; FLUSH PRIVILEGES;" mysql -uroot -p123456 CREATE USER 'sstuser' @'localhost' IDENTIFIED BY '123456' ; GRANT RELOAD, LOCK TABLES, PROCESS, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'sstuser' @'localhost' ; FLUSH PRIVILEGES; exit
这里修改后root密码,以及创建了sst账号,后面等其他节点加入到集群来,会同步过去
启动其他节点
操作节点:[除PXC1外的节点]
1 2 systemctl daemon-reload service mysqld start
1 2 3 4 5 [root@pxc2 ~]# service mysqld start Starting mysqld (via systemctl): [ OK ] [root@pxc3 ~]# service mysqld start Starting mysqld (via systemctl): [ OK ]
查看状态
操作节点:[哪个节点都行]
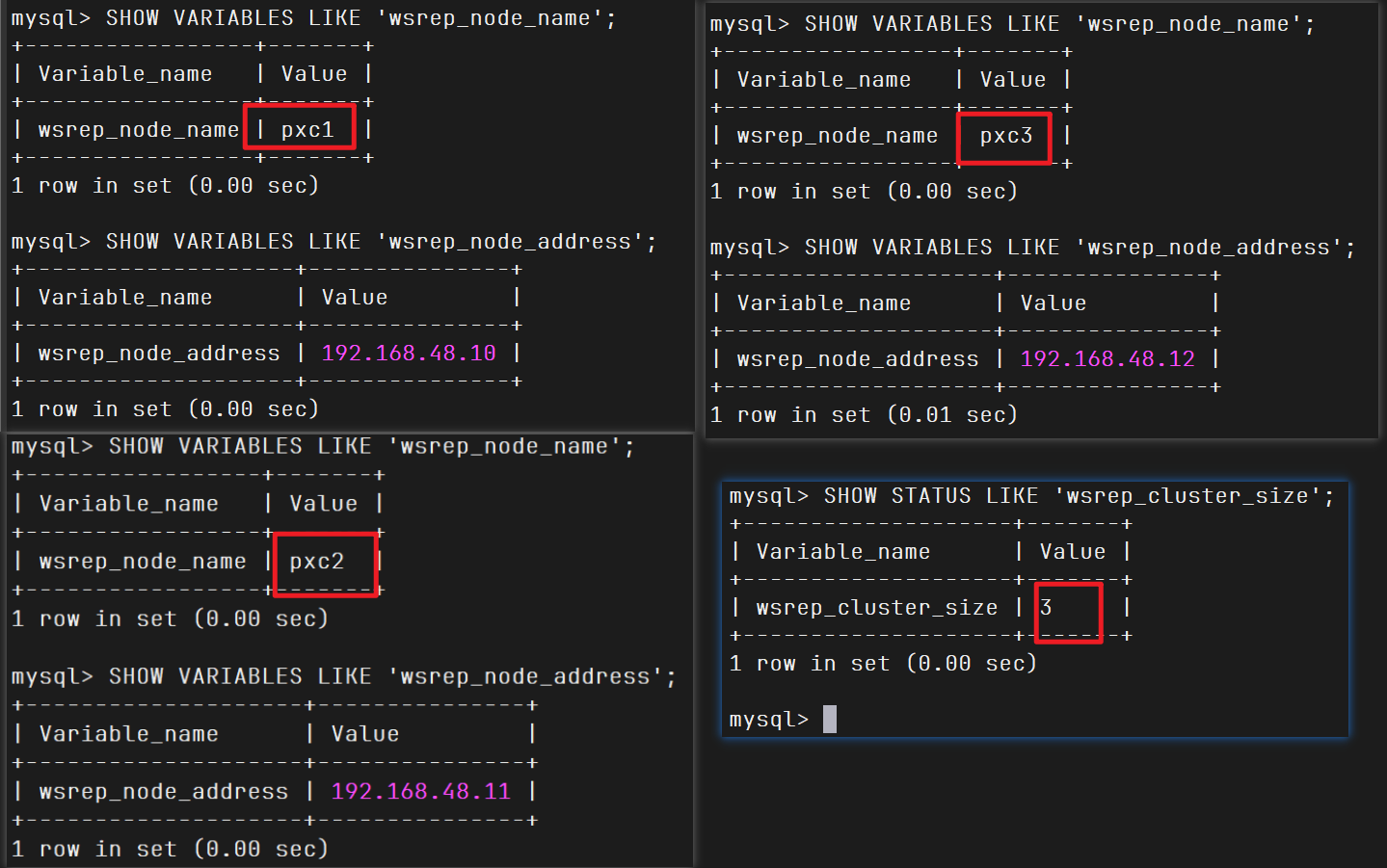
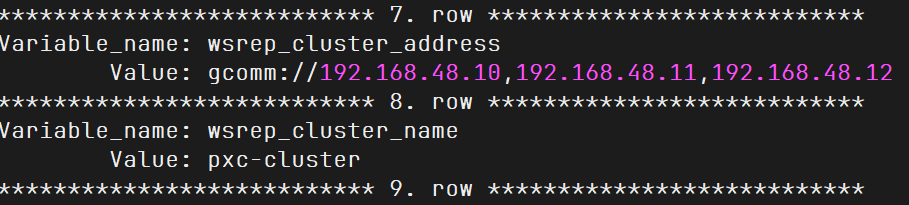
1 2 3 4 5 6 7 8 9 10 11 12 13 SHOW VARIABLES LIKE 'wsrep%' \G ...... *************************** 7. row *************************** Variable_name: wsrep_cluster_address Value: gcomm://192.168.48.10,192.168.48.11,192.168.48.12 *************************** 8. row *************************** Variable_name: wsrep_cluster_name Value: pxc-cluster *************************** 9. row *************************** ...... SHOW STATUS LIKE 'wsrep%' \G
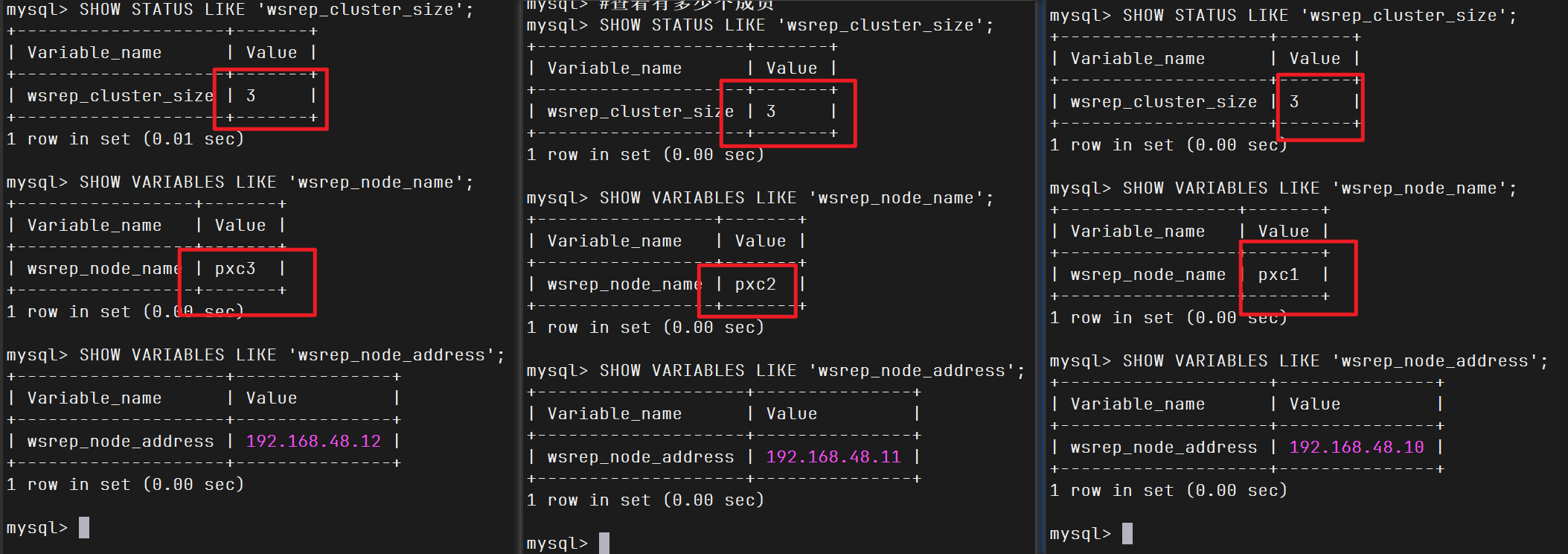
1 2 3 4 SHOW STATUS LIKE 'wsrep_cluster_size' ; SHOW VARIABLES LIKE 'wsrep_node_name' ; SHOW VARIABLES LIKE 'wsrep_node_address' ;
到这,pxc集群已经部署成功了
测试1
操作节点:[自己看注释]
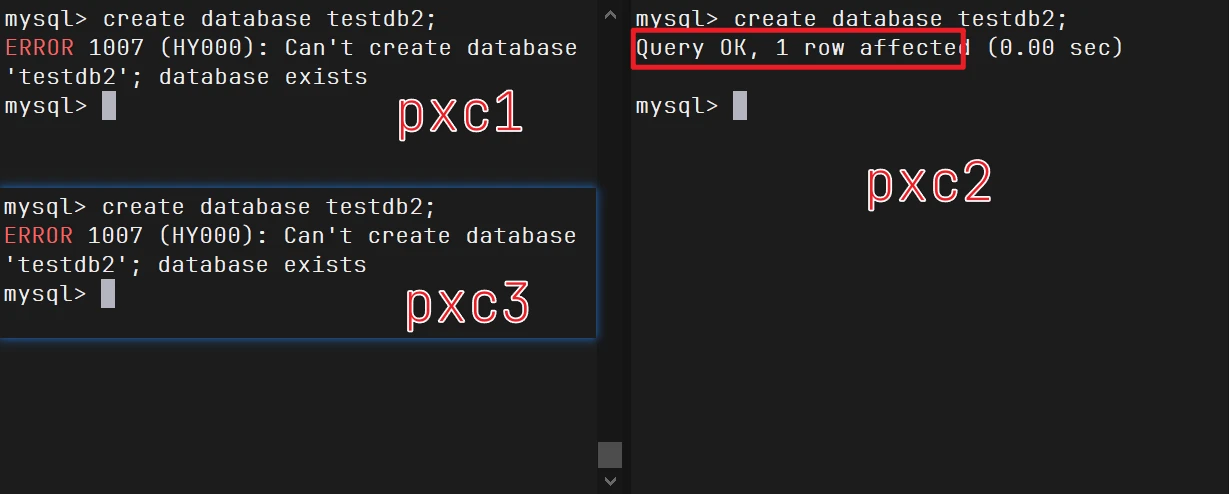
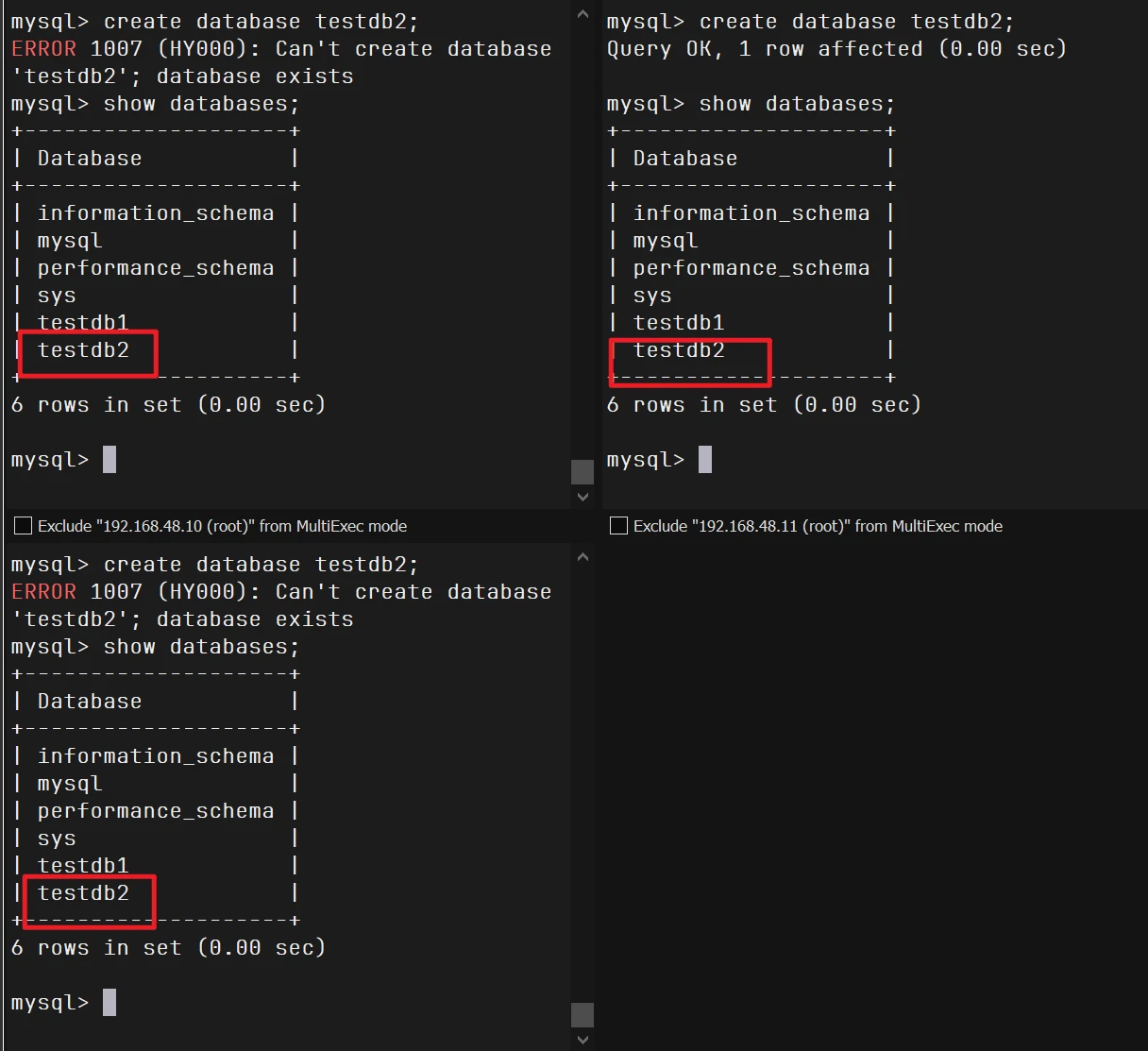
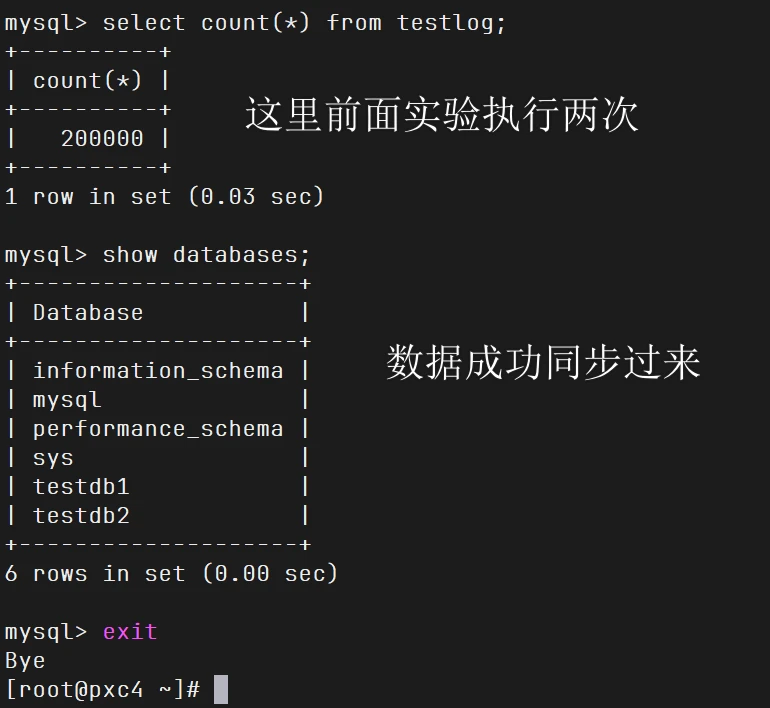
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 mysql> create database testdb1; Query OK, 1 row affected (0.00 sec) mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | | testdb1 | +--------------------+ 5 rows in set (0.00 sec) create database testdb2;
原因分析:
PXC 是一个 多主复制 的集群,所有节点理论上都可以写入,但实际上所有写请求会通过 Paxos 协议(即 Galera 协议)实现 全局同步提交 ,避免数据不一致。
当你同时在多个节点执行相同的创建语句时 ,可能发生下面的情形:
pxc2 上的 CREATE DATABASE testdb2; 第一个被提交并被整个集群接受 。pxc1 和 pxc3 也在执行 CREATE DATABASE testdb2;,但此时这个数据库已经被 pxc2 成功创建并同步过来了。所以 pxc1 和 pxc3 收到同步信息后,本地再执行时就发现数据库已存在,报错 1007。
注意:这个错误并不是复制失败,而是并发写入冲突导致的“重复创建”错误。
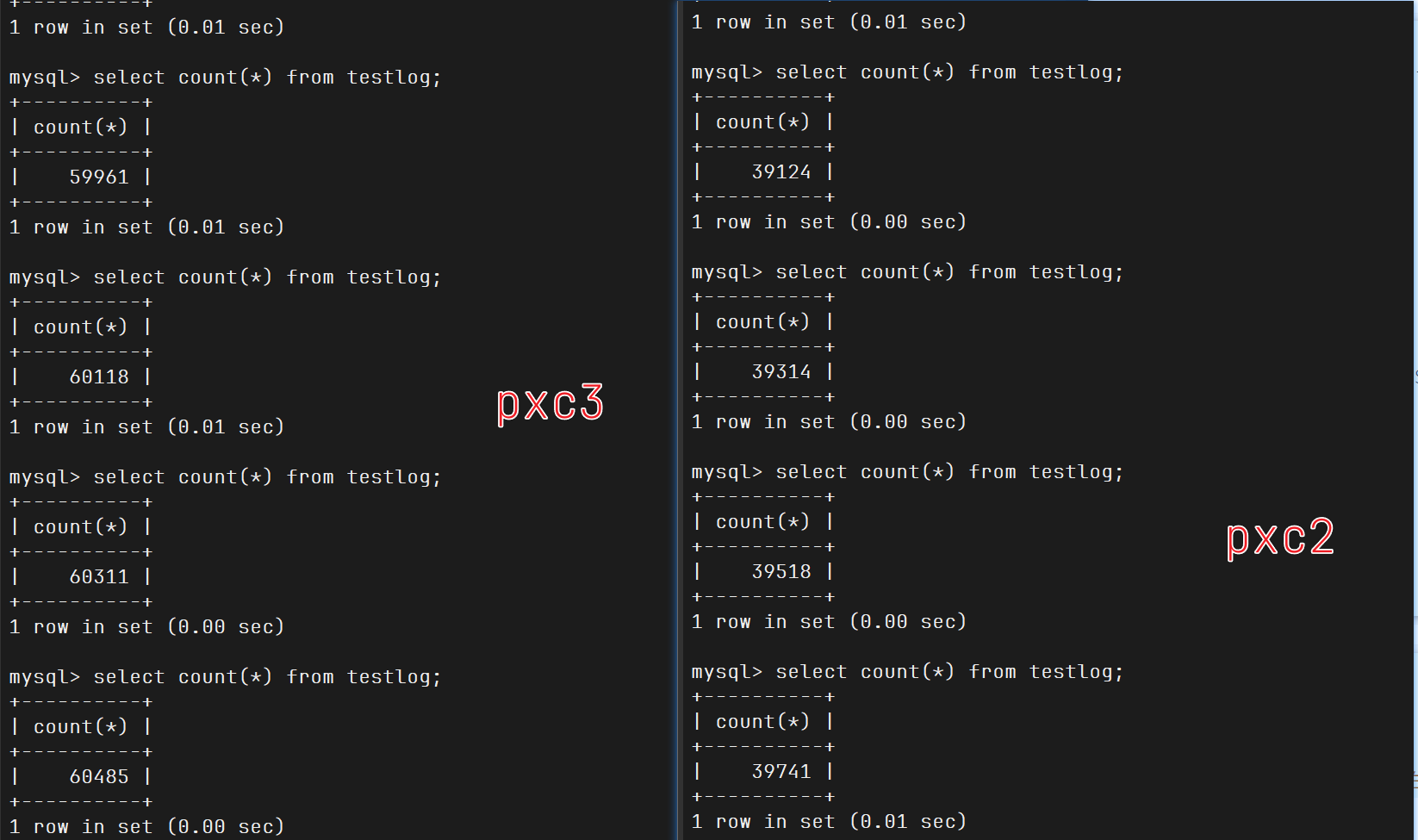
测试复制时间
你先运行我下面sql代码,要退出mysql,在终端运行,直接全选复制执行这个代码块
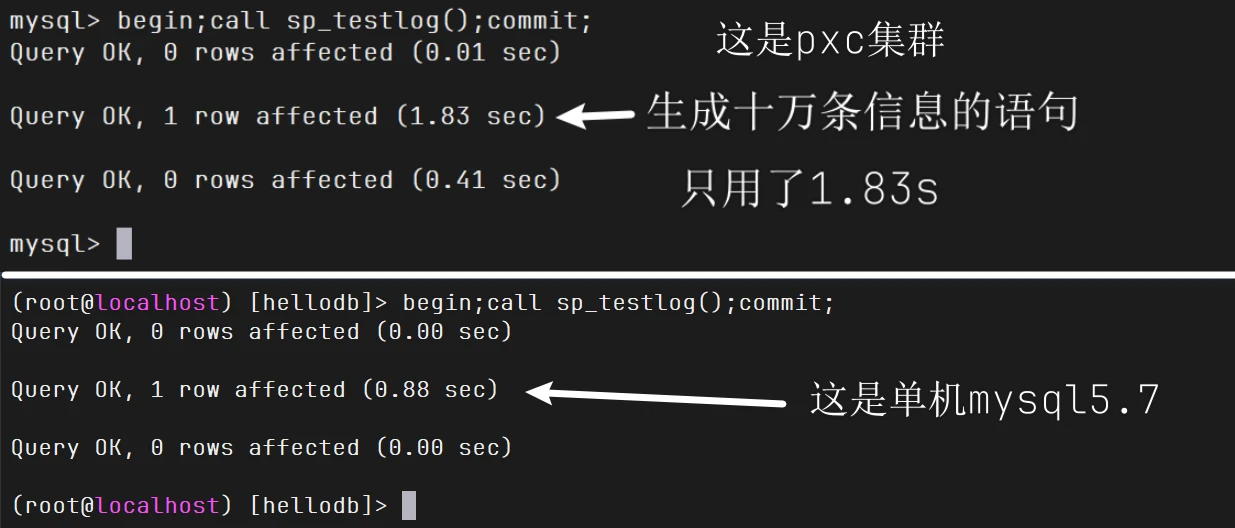
1 2 3 4 5 6 7 8 9 10 11 12 13 14 cat > testlog.sql<<"EOF" create table testlog (id int auto_increment primary key,name char(10),salary int default 20); delimiter $$ create procedure sp_testlog() begin declare i int;set i = 1; while i <= 100000 do insert into testlog(name,salary) values (concat('wang' ,FLOOR(RAND() * 100000)),FLOOR(RAND() * 1000000)); set i = i +1; end while ; end$$ delimiter ; EOF
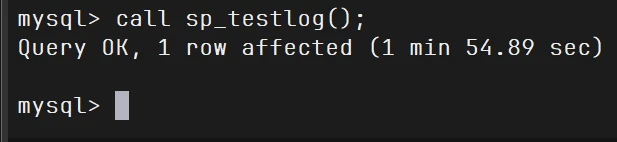
1 2 3 4 5 6 7 8 9 [root@pxc1 ~]# ls testlog.sql testlog.sql mysql -uroot -p123456 testdb1 < testlog.sql mysql -uroot -p123456 testdb1 call sp_testlog();
他在pxc1调用函数,不断生成信息插入到testlog表,然后复制到别的节点
一看pxc1用了这么长时间
这就是多节点,每提交一次命令就是一个事务,然后进行全局校验,十万次就是十万次全局校验,三个节点就是三十万次校验,所以要这么长的时间
为此我特地找了一个单节点的mysql5.7来测试一下,只用了15s
如何优化呢?你想一下,既然每提交一次就是一次事务,那全部放进事务里你
1 begin;call sp_testlog();commit;
测试高可用
当我将pxc1进行关闭mysql时,其他节点仍然可以查看数据等操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 [root@pxc1 ~]# service mysqld stop Reloading systemd: [ OK ] Stopping mysqld (via systemctl): [ OK ] [root@pxc1 ~]# use testdb2;create table test (id int primary key); mysql> insert into test values(1);select * from test ; Query OK, 1 row affected (0.02 sec) +----+ | id | +----+ | 1 | +----+ 1 row in set (0.00 sec) use testdb2;select * from test ; mysql> use testdb2;select * from test ; Database changed +----+ | id | +----+ | 1 | +----+ 1 row in set (0.00 sec)
当我在对pxc2再次模拟一个宕机,可用的就两台了
1 [root@pxc2 ~]# service mysqld stop
1 2 3 4 5 6 7 8 9 mysql> insert into test values(2);select * from test ; +----+ | id | +----+ | 1 | | 2 | +----+
当我回复前面两个节点时
1 2 3 4 5 6 7 8 9 10 11 12 13 14 service mysqld start mysql> use testdb2;select * from test ; Database changed +----+ | id | +----+ | 1 | | 2 | +----+ 2 rows in set (0.00 sec)
这就是高可用,哪怕你节点断了,再次回复时依然可以用
部署新增节点
操作节点:[pxc4]
将新增节点,自己根据前面的步骤再来一次
当做到2.2.7每个节点的配置文件 ,你就要更新节点信息了,注意是所有节点都要更新,但是不要关掉正在运行的节点,就更新就行了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 cluster_nodes="192.168.48.10,192.168.48.11,192.168.48.12,192.168.48.13" sst_user="sstuser" sst_pass="123456" node_name=$(hostname) node_ip=$(ip route get 1 | awk '{print $7; exit}' ) server_id=${node_ip##*.} cat > /etc/my.cnf <<EOF [client] # 客户端配置段 # 指定客户端使用的本地 socket 文件路径 socket=/usr/local/pxc/tmp/mysql.sock [mysqld] # 服务端配置段 # 设置该节点的唯一 server-id(一般取 IP 的最后一段) server-id=$server_id # 指定数据库的数据文件存放目录 datadir=/usr/local/pxc/data # 指定服务端使用的 socket 文件路径 socket=/usr/local/pxc/tmp/mysql.sock # 指定错误日志文件路径 log-error=/usr/local/pxc/logs/mysqld.log # 指定进程 ID 文件路径 pid-file=/usr/local/pxc/data/mysqld.pid # 开启二进制日志并设置日志文件路径 log-bin=/usr/local/pxc/logs/qybin # 设置二进制日志格式为 ROW(PXC 要求) binlog_format=ROW # 指定 Galera 的共享库路径 wsrep_provider=/usr/local/pxc/lib/libgalera_smm.so # 指定集群中所有节点的 IP 列表 wsrep_cluster_address=gcomm://$cluster_nodes # 设置默认存储引擎为 InnoDB default_storage_engine=InnoDB # 设置用于复制的线程数 wsrep_slave_threads=8 # 启用冲突检测日志 wsrep_log_conflicts # 设置自增锁模式为 2(PXC 推荐) innodb_autoinc_lock_mode=2 # 当前节点用于集群通信的 IP 地址 wsrep_node_address=$node_ip # 设置集群名称,所有节点必须一致 wsrep_cluster_name=pxc-cluster # 设置当前节点的名称 wsrep_node_name=$node_name # 启用 PXC 严格模式,防止非事务引擎等问题 pxc_strict_mode=ENFORCING # 设置 SST(状态快照传输)的方法为 xtrabackup-v2 wsrep_sst_method=xtrabackup-v2 # 配置 SST 用户名和密码 wsrep_sst_auth="$sst_user:$sst_pass" EOF chown -R mysql:mysql /usr/local/pxc
部署到2.2.8 初始化mysql 然后启动节点
1 2 [root@pxc4 ~]# service mysqld start Starting mysqld (via systemctl): [ OK ]
重启集群
当你所有的节点都关闭了或者宕机了,你做好恢复准备是不能直接启动的
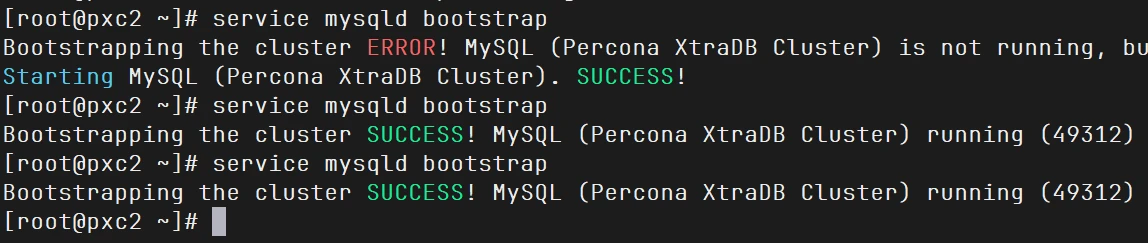
1 2 3 4 5 6 [root@pxc2 ~]# service mysqld bootstrap Bootstrapping the cluster ERROR! MySQL (Percona XtraDB Cluster) is not running, but lock fi Starting MySQL (Percona XtraDB Cluster)...... ERROR! The server quit without updating PID f ERROR! MySQL (Percona XtraDB Cluster) server startup failed!
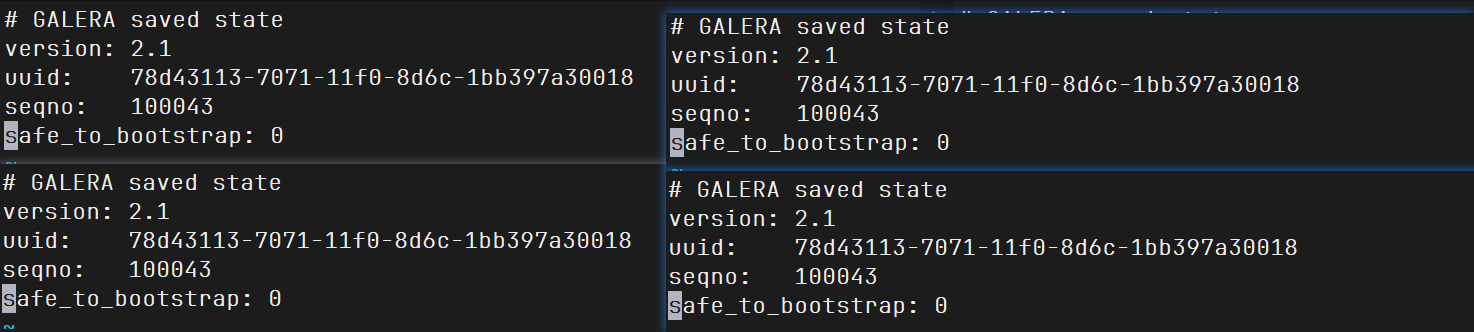
grastate.dat 是 Percona XtraDB Cluster(PXC) 和 Galera Cluster 中的一个关键元数据文件,位于 MySQL 数据目录中(如 /var/lib/mysql/grastate.dat 或 /usr/local/pxc/data/grastate.dat)。它用于记录节点上次关闭时的集群状态
uuid:节点所属的 Galera 集群 UUIDseqno:节点关闭时的最新事务序号(sequence number),越大表示数据越新safe_to_bootstrap:是否可以用该节点来引导整个集群:1 表示可以,0 表示不推荐
1 cat /usr/local/pxc/data/grastate.dat
四个节点全是0
我修改其中一个节点的safe_to_bootstrap为1就行了,比如说修改pxc2为safe_to_bootstrap: 1,再次启动,成功启动
1 service mysqld bootstrap
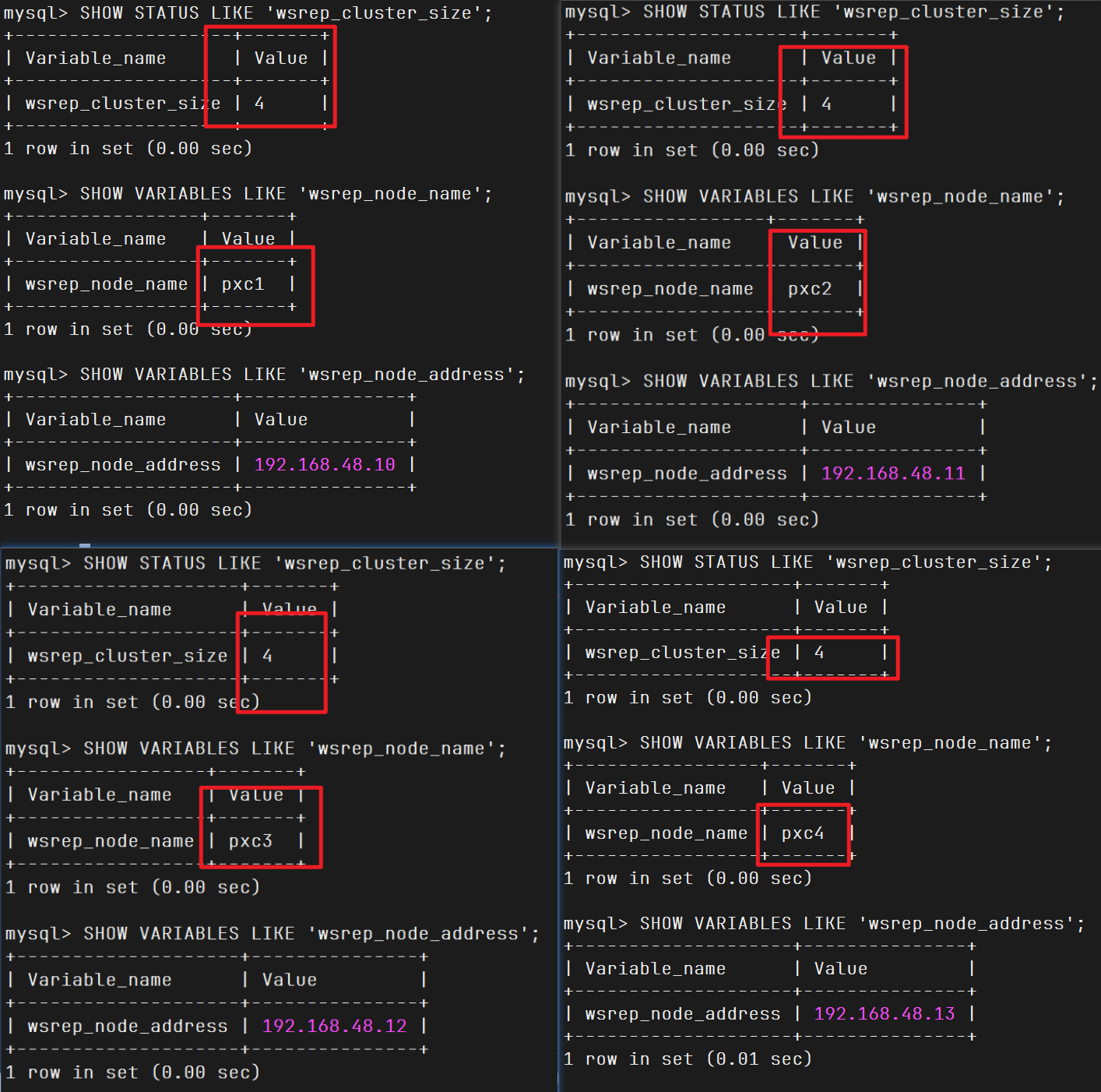
其他节点也加入集群
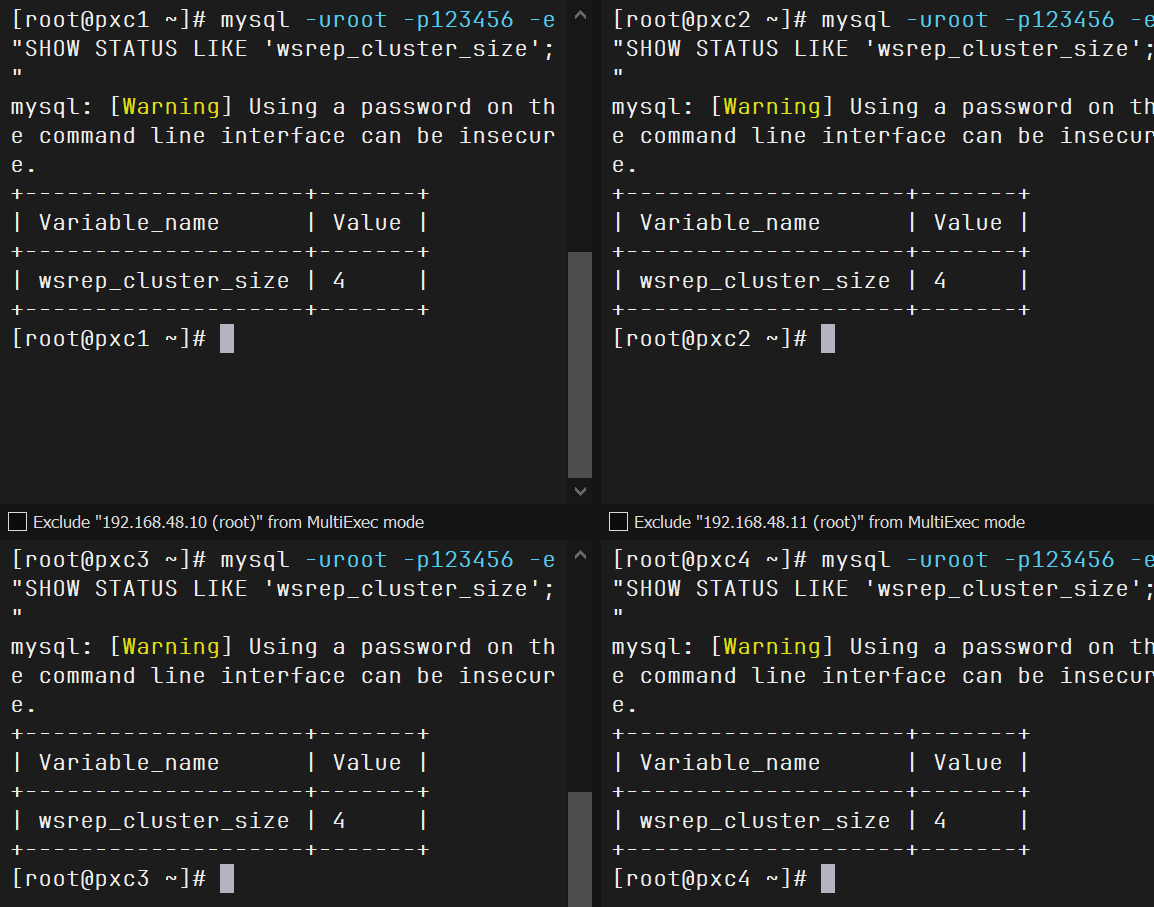
查看状态,集群健康
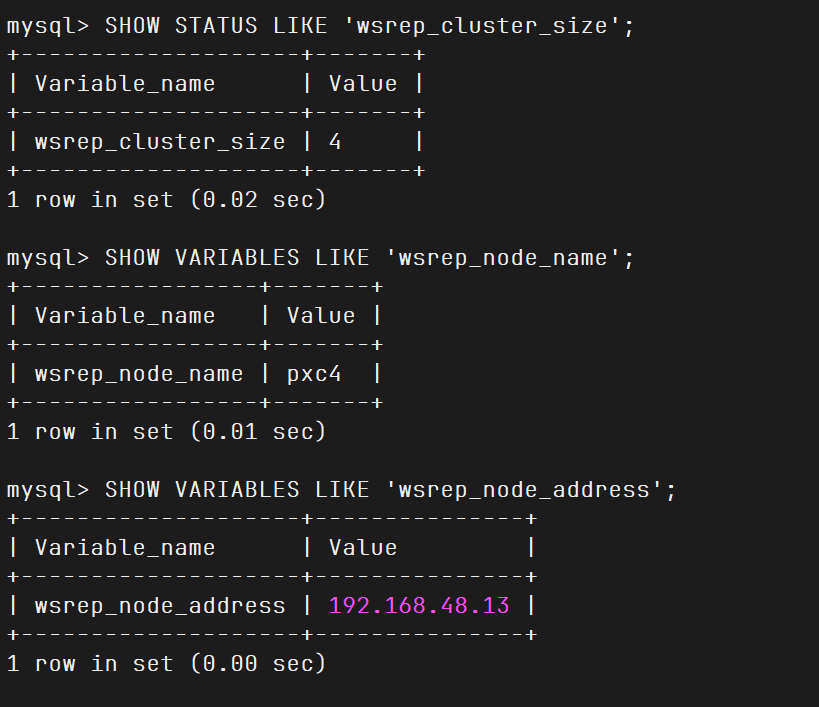
1 mysql -uroot -p123456 -e"SHOW STATUS LIKE 'wsrep_cluster_size';"
centos7 RPM部署PXC5.7
这是本次实验会用到的资源,请你提前下载好,上传到每个节点的/root下,因为我现在是用的是root用户
官网下载:percona.com
架构图
所有系统都是centos7
主机名
ip
内存
硬盘
pxc1
192.168.48.10
3G
100G
pxc2
192.168.48.11
3G
100G
pxc3
192.168.48.12
3G
100G
pxc4
192.168.48.13
3G
100G
关闭防火墙和SELinux,保证时间同步,自己改主机名
注意:如果已经安装MySQL,必须卸载
安装pxc软件包
操作节点:[所有节点]
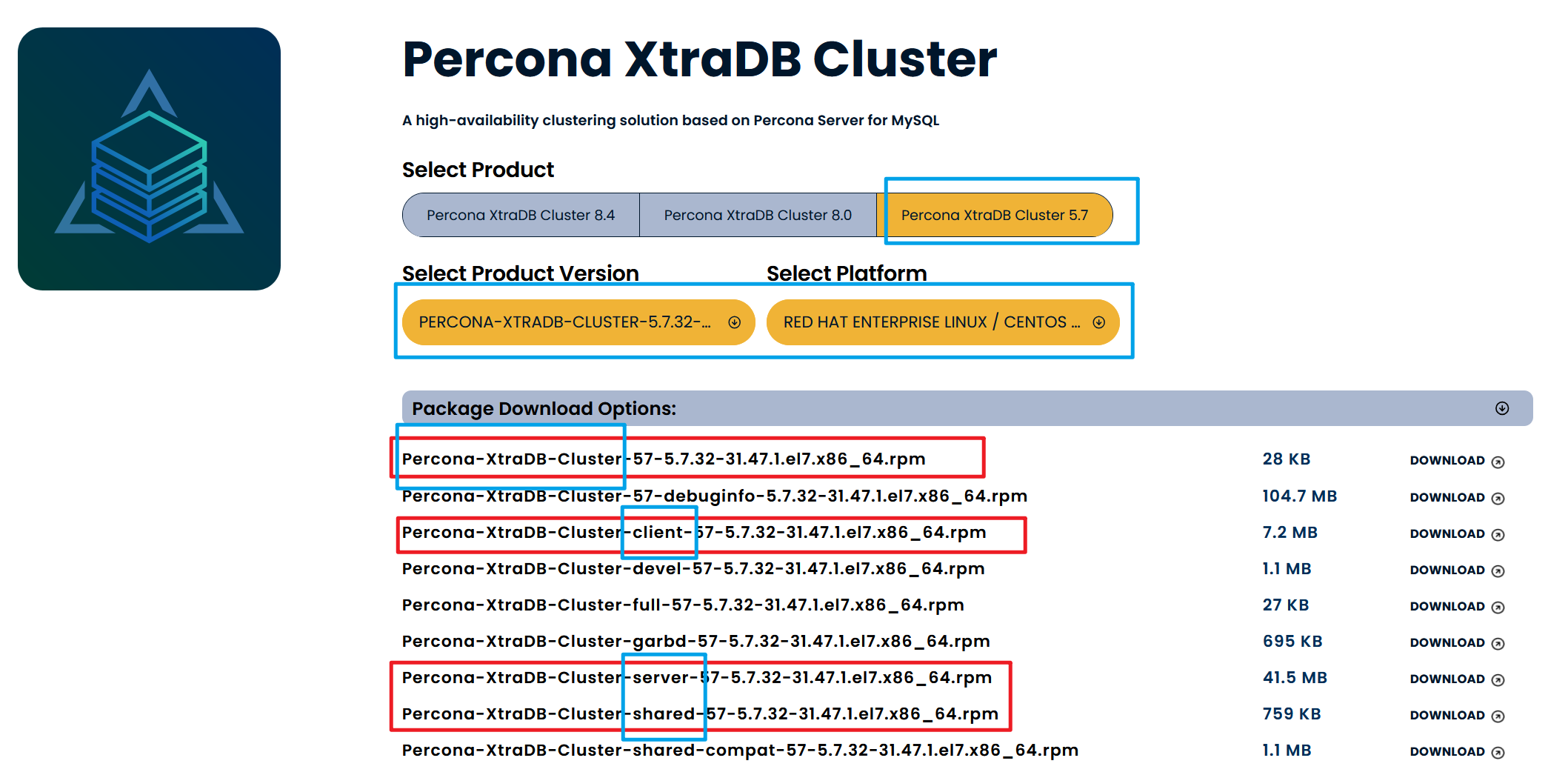
1 2 3 4 5 6 yum install -y https://repo.percona.com/yum/percona-release-latest.noarch.rpm percona-release setup -y ps-57 yum localinstall Percona-XtraDB-Cluster-57-5.7.32-31.47.1.el7.x86_64.rpm \ Percona-XtraDB-Cluster-client-57-5.7.32-31.47.1.el7.x86_64.rpm \ Percona-XtraDB-Cluster-server-57-5.7.32-31.47.1.el7.x86_64.rpm \ Percona-XtraDB-Cluster-shared-57-5.7.32-31.47.1.el7.x86_64.rpm -y
都是可以成功安装的哦
设置配置文件
操作节点:[PXC1,PXC2,PXC3]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 cluster_nodes="192.168.48.10,192.168.48.11,192.168.48.12" sst_user="sstuser" sst_pass="123456" node_name=$(hostname) node_ip=$(ip route get 1 | awk '{print $7; exit}' ) server_id=${node_ip##*.} cat >/etc/percona-xtradb-cluster.conf.d/wsrep.cnf<<EOF [mysqld] # Galera插件路径 wsrep_provider=/usr/lib64/galera3/libgalera_smm.so # 集群节点地址,多个节点逗号分隔 wsrep_cluster_address=gcomm://$cluster_nodes # binlog格式设为ROW,保证数据同步准确 binlog_format=ROW # 默认存储引擎为InnoDB default_storage_engine=InnoDB # 并发复制线程数,提升复制效率 wsrep_slave_threads=8 # 记录冲突日志,便于调试 wsrep_log_conflicts # InnoDB自增锁模式,推荐2提高并发性能 innodb_autoinc_lock_mode=2 # 当前节点IP wsrep_node_address=$node_ip # 集群名称,保持一致 wsrep_cluster_name=pxc-cluster # 当前节点名称 wsrep_node_name=$node_name # 开启严格模式,保证数据一致性 pxc_strict_mode=ENFORCING # SST同步方式,使用xtrabackup-v2 wsrep_sst_method=xtrabackup-v2 # SST同步认证账号密码 wsrep_sst_auth="$sst_user:$sst_pass" EOF cat >/etc/percona-xtradb-cluster.conf.d/mysqld.cnf <<EOF [client] # MySQL客户端socket文件位置 socket=/var/lib/mysql/mysql.sock [mysqld] # 唯一server_id,通常使用IP最后一段 server-id=$server_id # 数据目录 datadir=/var/lib/mysql # MySQL socket文件 socket=/var/lib/mysql/mysql.sock # 错误日志文件路径 log-error=/var/log/mysqld.log # PID文件路径 pid-file=/var/run/mysqld/mysqld.pid # 开启二进制日志,支持复制 log-bin # 记录从库更新,保证复制正确 log_slave_updates # 过期日志自动清理,单位为天 expire_logs_days=7 # 禁止符号链接,安全设置 symbolic-links=0 EOF
启动第一个节点
操作节点:[PXC1],拿个节点都行,你看着来
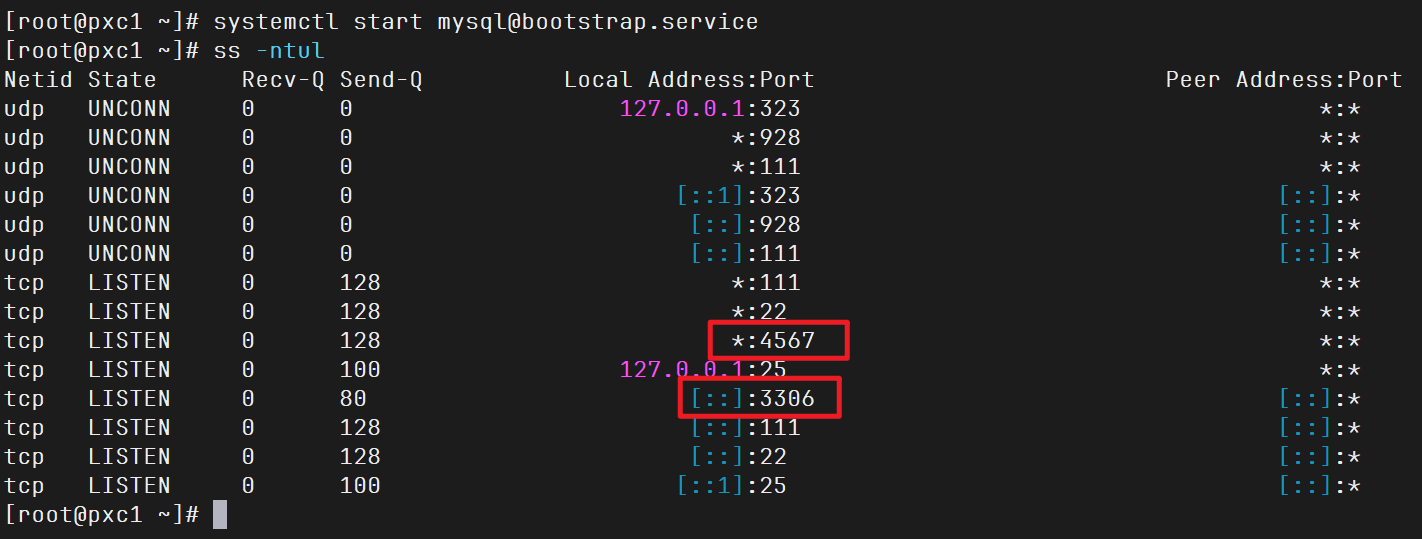
1 2 systemctl start mysql@bootstrap.service ss -ntul
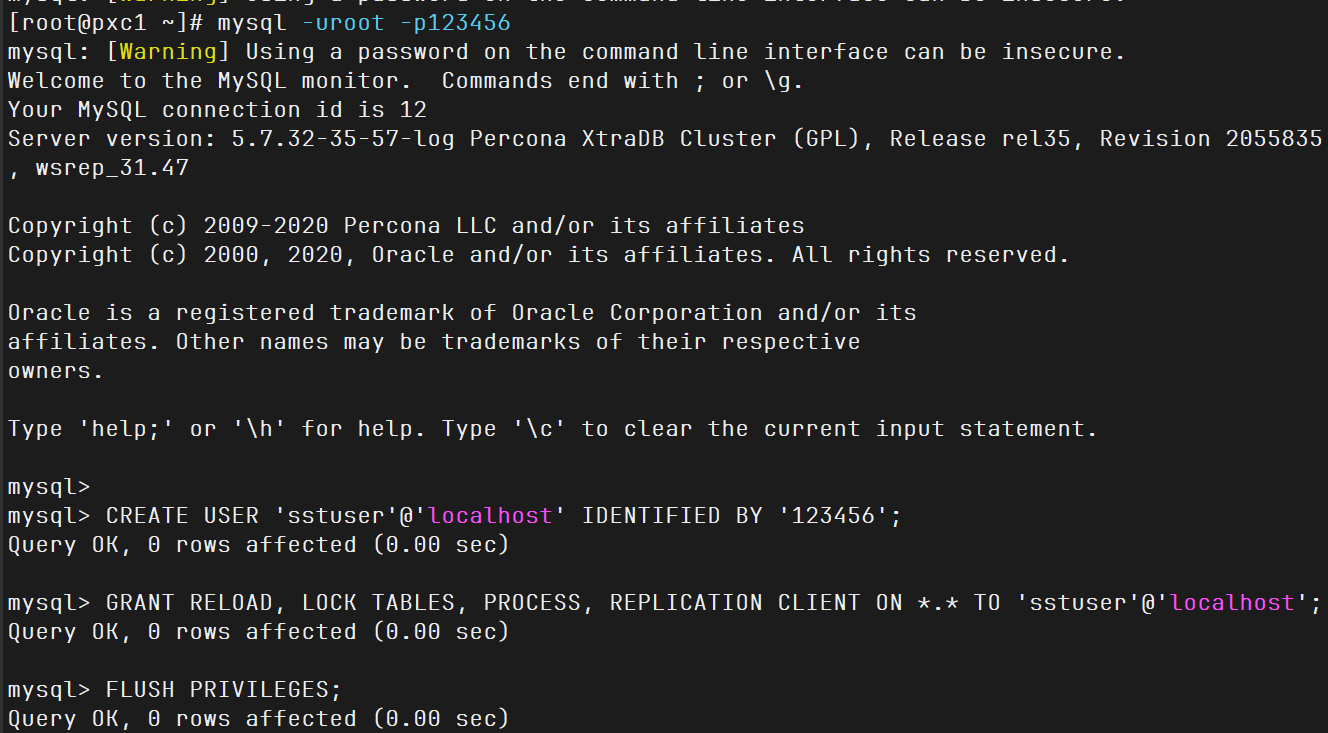
修改root密码,创建sst账号
1 2 3 4 5 6 7 8 9 10 11 12 13 14 MYSQL_PASSWD="123456" MYSQL_OLD_PASSWD=$(awk '/temporary password/{print $NF}' /var/log/mysqld.log) mysql -uroot -p"$MYSQL_OLD_PASSWD " --connect-expired-password -e "ALTER USER 'root'@'localhost' IDENTIFIED BY '123456'; FLUSH PRIVILEGES;" mysql -uroot -p123456 CREATE USER 'sstuser' @'localhost' IDENTIFIED BY '123456' ; GRANT RELOAD, LOCK TABLES, PROCESS, REPLICATION CLIENT ON *.* TO 'sstuser' @'localhost' ; FLUSH PRIVILEGES; SHOW VARIABLES LIKE 'wsrep%' \G SHOW STATUS LIKE 'wsrep%' \G show status like 'wsrep%' ;
这里修改后root密码,以及创建了sst账号,后面等其他节点加入到集群来,会同步过去
其他节点加入集群
查看状态
1 2 3 4 5 mysql -uroot -p123456 SHOW STATUS LIKE 'wsrep_cluster_size' ; SHOW VARIABLES LIKE 'wsrep_node_name' ; SHOW VARIABLES LIKE 'wsrep_node_address' ;
集群健康
测试
测试,请前往2.2.13 测试1
你要注意,这个测试是二进制部署pxc的测试内容,就只有路径不一样还有启动方式关闭集群方式不一样,你自己要看一下,只有在mysql里的插入数据等操作都是可以这里运行的,自己理解一下,我觉得你能有兴趣看到这里,说明前面的你也有认真看,我大部分的理解可能都在前一个章节,加油特种兵
部署新增节点
操作节点:[pxc4]
做好2.3.2安装pxc软件包 和2.3.3设置配置文件
注意,2.3.3设置配置文件,要新增节点信息了喔,加上pxc4的ip地址,然后全部节点都更新文件,但是不要重启已运行的节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 cluster_nodes="192.168.48.10,192.168.48.11,192.168.48.12,192.168.48.13" sst_user="sstuser" sst_pass="123456" node_name=$(hostname) node_ip=$(ip route get 1 | awk '{print $7; exit}' ) server_id=${node_ip##*.} cat >/etc/percona-xtradb-cluster.conf.d/wsrep.cnf<<EOF [mysqld] # Galera插件路径 wsrep_provider=/usr/lib64/galera3/libgalera_smm.so # 集群节点地址,多个节点逗号分隔 wsrep_cluster_address=gcomm://$cluster_nodes # binlog格式设为ROW,保证数据同步准确 binlog_format=ROW # 默认存储引擎为InnoDB default_storage_engine=InnoDB # 并发复制线程数,提升复制效率 wsrep_slave_threads=8 # 记录冲突日志,便于调试 wsrep_log_conflicts # InnoDB自增锁模式,推荐2提高并发性能 innodb_autoinc_lock_mode=2 # 当前节点IP wsrep_node_address=$node_ip # 集群名称,保持一致 wsrep_cluster_name=pxc-cluster # 当前节点名称 wsrep_node_name=$node_name # 开启严格模式,保证数据一致性 pxc_strict_mode=ENFORCING # SST同步方式,使用xtrabackup-v2 wsrep_sst_method=xtrabackup-v2 # SST同步认证账号密码 wsrep_sst_auth="$sst_user:$sst_pass" EOF cat >/etc/percona-xtradb-cluster.conf.d/mysqld.cnf <<EOF [client] # MySQL客户端socket文件位置 socket=/var/lib/mysql/mysql.sock [mysqld] # 唯一server_id,通常使用IP最后一段 server-id=$server_id # 数据目录 datadir=/var/lib/mysql # MySQL socket文件 socket=/var/lib/mysql/mysql.sock # 错误日志文件路径 log-error=/var/log/mysqld.log # PID文件路径 pid-file=/var/run/mysqld/mysqld.pid # 开启二进制日志,支持复制 log-bin # 记录从库更新,保证复制正确 log_slave_updates # 过期日志自动清理,单位为天 expire_logs_days=7 # 禁止符号链接,安全设置 symbolic-links=0 EOF
查看节点状态
1 2 3 4 5 mysql -uroot -p123456 SHOW STATUS LIKE 'wsrep_cluster_size' ; SHOW VARIABLES LIKE 'wsrep_node_name' ; SHOW VARIABLES LIKE 'wsrep_node_address' ;
至此PXC实验完结
千屹博客旗下的所有文章,是通过本人课堂学习和课外自学所精心整理的知识巨著




 微信
微信 支付宝
支付宝