Hadoop部署
本笔记分伪分布和分布式两大块,但建议从头开始观看
文章所需资源可点击这里 下载
伪分布
单节点 masteryjx48 (Centos 7.9)
名称
ip1(NAT)
内存
硬盘
masteryjx48
192.168.48.11
5G
100G
基本配置
本地yum配置,自行挂载本地Centos7.9镜像
1 2 3 4 5 6 7 8 9 10 11 12 13 mkdir repo.bak mv /etc/yum.repos.d/* repo.bak/ mount /dev/cdrom /mnt cat >>/etc/yum.repos.d/local.repo<<EOF [local] name=local baseurl=file:///mnt gpgcheck=0 enabled=1 EOF yum clean all && yum makecache systemctl disable firewalld --now sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux
更改hosts
1 echo "192.168.48.11 masteryjx48" >> /etc/hosts
配置主机名
1 hostnamectl set-hostname masteryjx48 && bash
配置ssh免密登入
1 2 3 4 5 ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys ssh-copy-id masteryjx48 ssh masteryjx48 exit
安装JAVA环境
1 2 3 4 5 6 mkdir /usr/lib/jvm tar -xf /root/jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm echo "export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162" >> /etc/profile echo "export PATH=\$JAVA_HOME/bin:\$PATH" >> /etc/profile source /etc/profile java -version
安装Hadoop
1 2 3 4 5 6 tar -zxf hadoop-3.1.3.tar.gz -C /usr/local mv /usr/local/hadoop-3.1.3/ /usr/local/hadoop echo "export HADOOP_HOME=/usr/local/hadoop" >> /etc/profile echo "export PATH=\$HADOOP_HOME/bin/:\$HADOOP_HOME/sbin/:\$PATH" >> /etc/profile source /etc/profile hadoop version
打个快照,方便做分布式部署,做分布式的直接跳到2.分布式
编写配置文件
编写cort-site.yaml文件
1 2 3 4 5 6 7 8 9 10 11 12 [root@masteryjx48 ~]# cat /usr/local/hadoop/etc/hadoop/core-site.xml <configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://masteryjx48:9000</value> </property> </configuration>
编写hdfs-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [root@masteryjx48 ~]# cat /usr/local/hadoop/etc/hadoop/hdfs-site.xml <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration>
启动hdfs服务
添加环境变量
1 2 3 4 5 6 echo "export HDFS_NAMENODE_USER=root" >> /etc/profile echo "export HDFS_DATANODE_USER=root" >> /etc/profile echo "export HDFS_SECONDARYNAMENODE_USER=root" >> /etc/profile echo "export YARN_RESOURCEMANAGER_USER=root" >> /etc/profile echo "export YARN_NODEMANAGER_USER=root" >> /etc/profile source /etc/profile
修改hadoop配置文件
1 echo "export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162" >> /usr/local/hadoop/etc/hadoop/hadoop-env.sh
启动hadoop服务
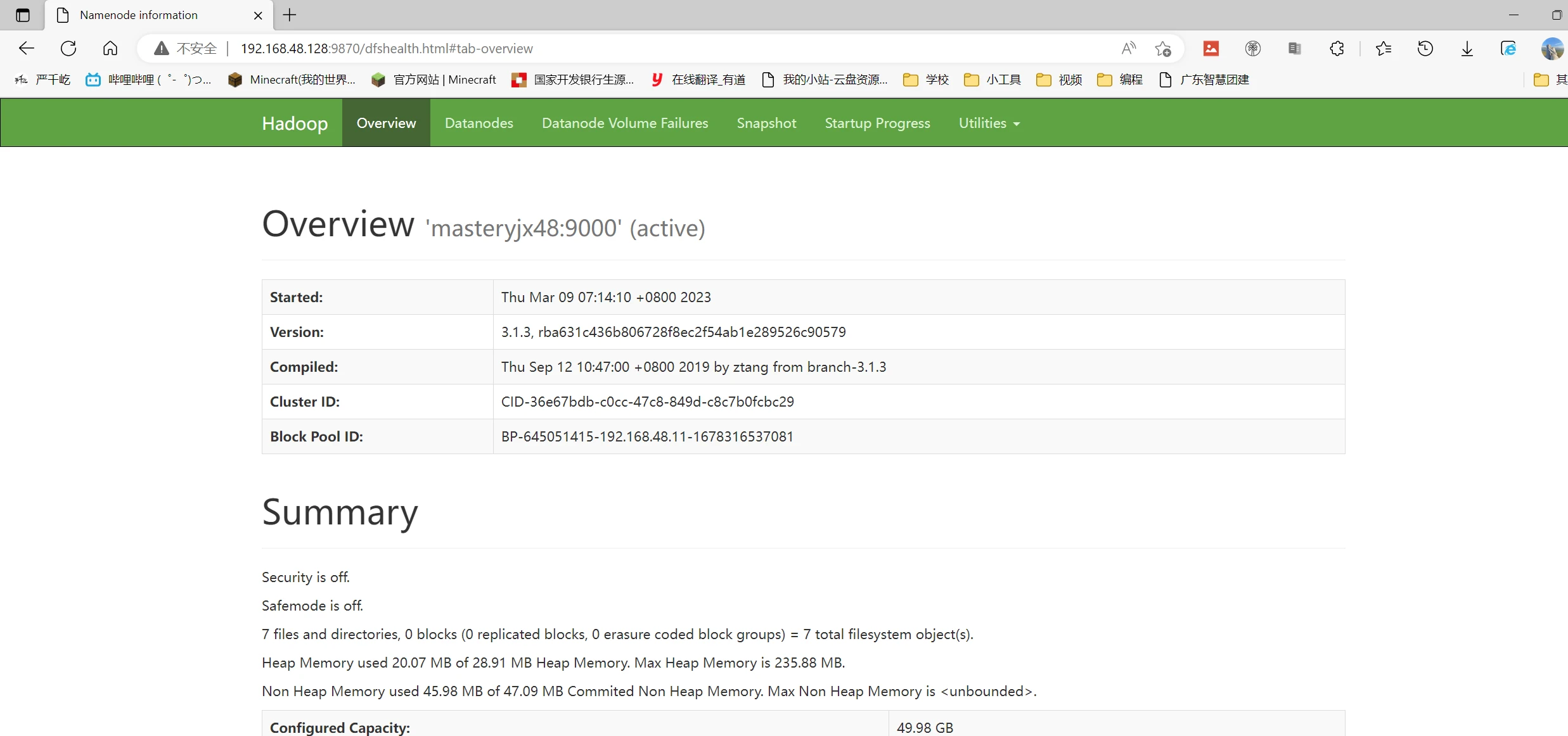
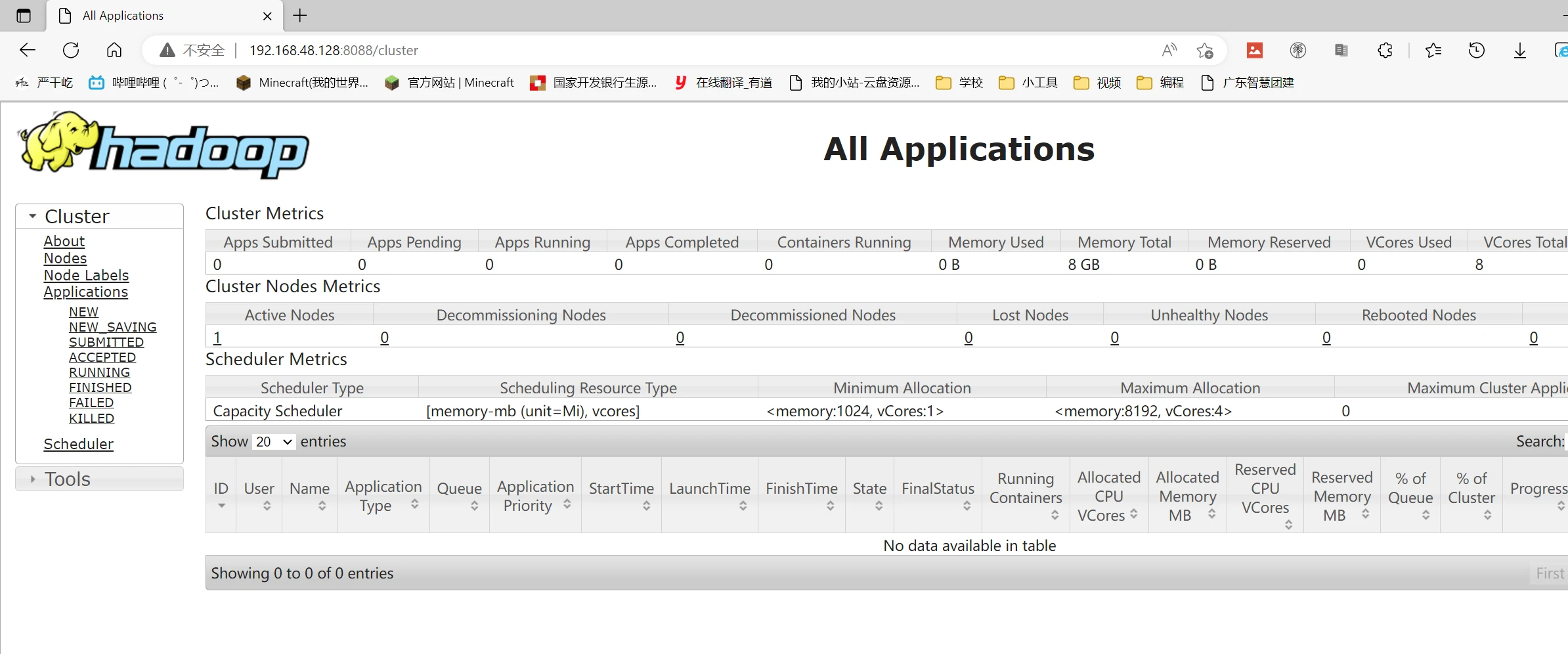
1 2 3 4 5 6 7 8 9 10 11 12 [root@masteryjx48 ~]# start-all.sh Starting namenodes on [masteryjx48] Last login: Thu Mar 9 07:12:02 CST 2023 on pts/0 Starting datanodes Last login: Thu Mar 9 07:14:08 CST 2023 on pts/0 Starting secondary namenodes [masteryjx48] Last login: Thu Mar 9 07:14:11 CST 2023 on pts/0 Starting resourcemanager Last login: Thu Mar 9 07:14:15 CST 2023 on pts/0 Starting nodemanagers Last login: Thu Mar 9 07:14:20 CST 2023 on pts/0
关闭hadoop服务 stop-dfs.sh
启动historyserver服务
1 mr-jobhistory-daemon.sh start historyserver
查看java进程
1 2 3 4 5 6 7 8 [root@masteryjx48 ~]# jps 9280 ResourceManager 8785 DataNode 9443 NodeManager 9014 SecondaryNameNode 8599 NameNode 11127 Jps 11034 JobHistoryServer
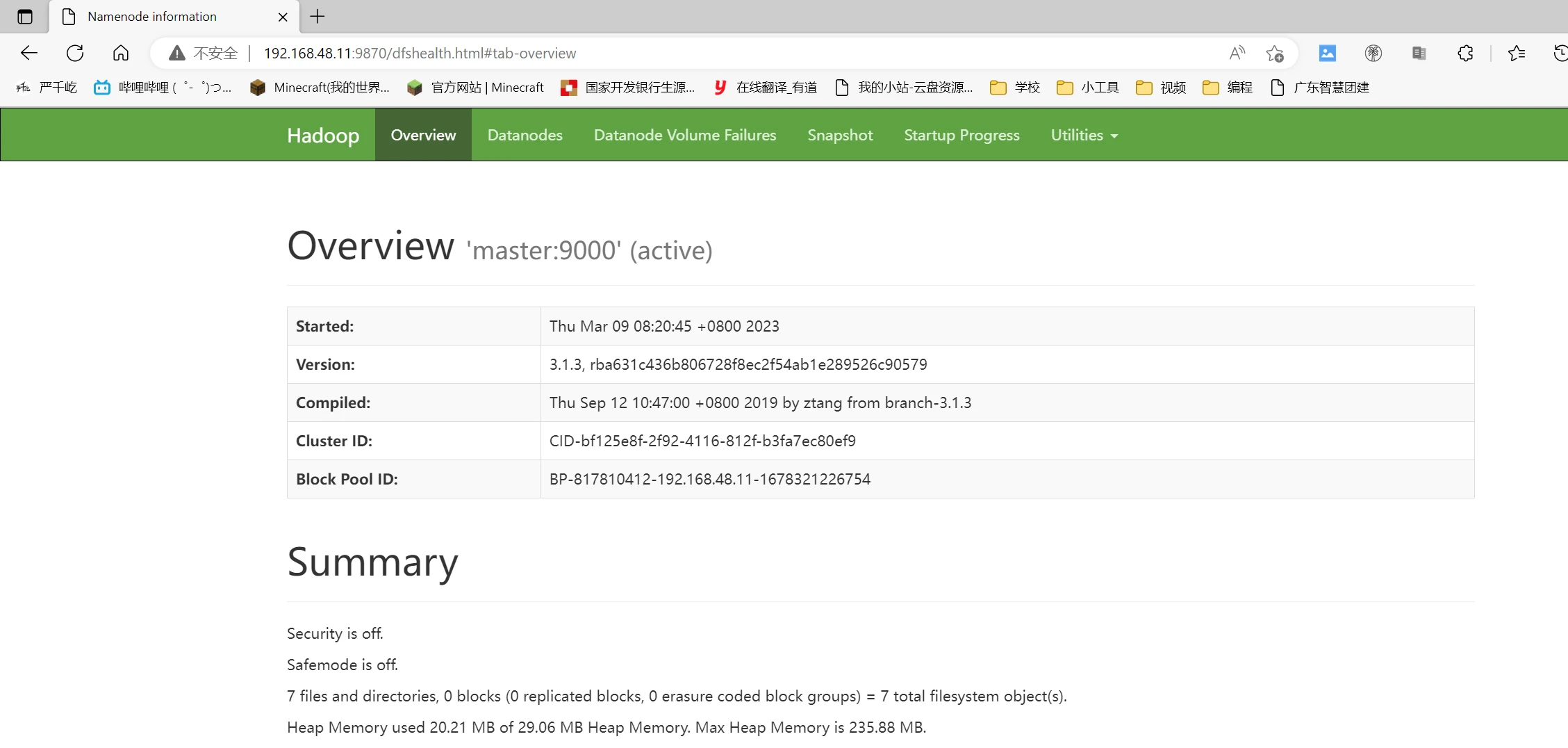
访问网页ip:9870查看hdfs
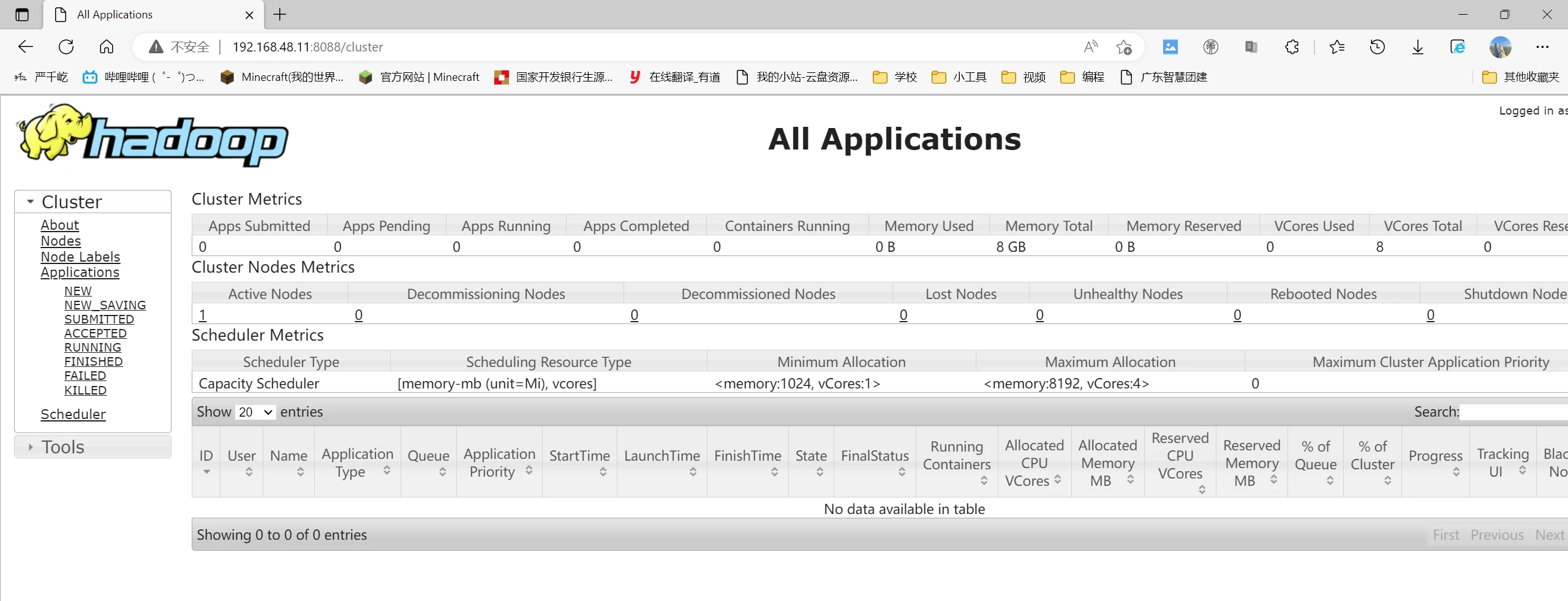
访问网页ip:8088查看hadoop
分布式
❗❗❗❗这里就克隆前面创建好的快照(1.6步骤),修改好ip
主机
ip
系统和软件
内存
master
192.168.48.11
Centos7.9、Hadoop
5G
slave1
192.168.48.12
Centos7.9、Hadoop
5G
环境配置
修改hosts 把之前添加的删掉
master
1 2 hostnamectl set-hostname master bash
slave1
1 2 3 4 5 hostnamectl set-hostname slave1 bash echo "192.168.48.11 master" >> /etc/hosts echo "192.168.48.12 slave1" >> /etc/hosts scp /etc/hosts root@master:/etc/hosts
SSH免密登入设置
master
1 2 3 4 5 6 7 8 ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys ssh master exit ssh-copy-id -i root@slave1 ssh slave1 ll exit
slave1
1 2 3 4 5 6 7 8 ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys ssh slave1 exit ssh-copy-id -i root@master ssh master ll exit
检查java和hadoop环境
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 master [root@master ~]# java -version java version "1.8.0_162" Java(TM) SE Runtime Environment (build 1.8.0_162-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode) [root@master ~]# hadoop version Hadoop 3.1.3 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579 Compiled by ztang on 2019-09-12T02:47Z Compiled with protoc 2.5.0 From source with checksum ec785077c385118ac91aadde5ec9799 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.1.3.jar slave1 [root@slave1 ~]# java -version java version "1.8.0_162" Java(TM) SE Runtime Environment (build 1.8.0_162-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode) [root@slave1 ~]# hadoop version Hadoop 3.1.3 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579 Compiled by ztang on 2019-09-12T02:47Z Compiled with protoc 2.5.0 From source with checksum ec785077c385118ac91aadde5ec9799 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.1.3.jar
修改配置文件
修改workers配置文件
1 2 3 [root@master hadoop]# cd /usr/local/hadoop/etc/hadoop [root@master hadoop]# cat workers slave1
修改core-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 [root@master hadoop]# cat core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> </configuration>
修改hdfs-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@master hadoop]# cat hdfs-site.xml <configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:50090</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration>
修改mapred-site.xml配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 [root@master hadoop]# cat mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> </configuration>
修改yarn-site.xml文件
1 2 3 4 5 6 7 8 9 10 11 [root@master hadoop]# cat yarn-site.xml <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
将上述配置拷贝到slave1上
master
1 2 3 4 5 6 cd /usr/local/hadoop/etc/hadoop/ scp core-site.xml slave1:/usr/local/hadoop/etc/hadoop/ scp hdfs-site.xml slave1:/usr/local/hadoop/etc/hadoop/ scp mapred-site.xml slave1:/usr/local/hadoop/etc/hadoop/ scp workers slave1:/usr/local/hadoop/etc/hadoop/ scp yarn-site.xml slave1:/usr/local/hadoop/etc/hadoop/
修改环境变量拷贝到slave1
master
1 2 3 4 5 6 7 8 echo "export HDFS_NAMENODE_USER=root" >> /etc/profile echo "export HDFS_DATANODE_USER=root" >> /etc/profile echo "export HDFS_SECONDARYNAMENODE_USER=root" >> /etc/profile echo "export YARN_RESOURCEMANAGER_USER=root" >> /etc/profile echo "export YARN_NODEMANAGER_USER=root" >> /etc/profile source /etc/profile scp /etc/profile slave1:/etc/profile source /etc/profile
修改hadoop 环境配置文件并将配置文件拷贝到slave1
1 2 3 echo "export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162" >> /usr/local/hadoop/etc/hadoop/hadoop-env.sh scp /usr/local/hadoop/etc/hadoop/hadoop-env.sh slave1:/usr/local/hadoop/etc/hadoop/hadoop-env.sh
集群配置启动
master初始化
启动hadoop
启动historyserver
1 mr-jobhistory-daemon.sh start historyserver
查看java进程
1 2 3 4 5 6 [root@master hadoop]# jps 35863 ResourceManager 2841 JobHistoryServer 39065 NameNode 39771 Jps 35597 SecondaryNameNode
1 2 3 4 [root@slave1 ~]# jps 5587 NodeManager 5492 DataNode 6215 Jps
千屹博客旗下的所有文章,是通过本人课堂学习和课外自学所精心整理的知识巨著

 微信
微信 支付宝
支付宝